スケーリングされた指示によるファインチューニングされた言語モデル
What's new?
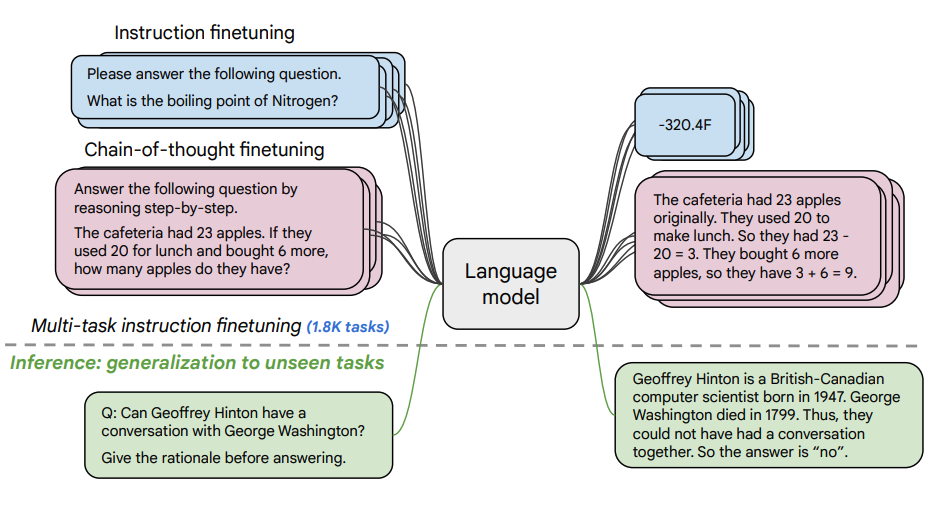
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
本論文は、指示によるファインチューニング (opens in a new tab)のスケーリングの利点を探求し、PaLM、T5などのさまざまなモデル、プロンプトセットアップ(ゼロショット、フューショット、CoT)、およびベンチマーク(MMLU、TyDiQA)でのパフォーマンスの向上について説明しています。これには、以下の側面が探究されます:タスク数のスケーリング(1.8Kタスク)、モデルサイズのスケーリング、および思考連鎖データのファインチューニング(9つのデータセットを使用)。
ファインチューニング手順:
- 1.8Kタスクが指示文としてフレーズ化され、モデルのファインチューニングに使用されます。
- 実例あり・なし、CoTあり・なしの両方を使用します。
ファインチューニングタスクと保持タスクは以下に示されています。
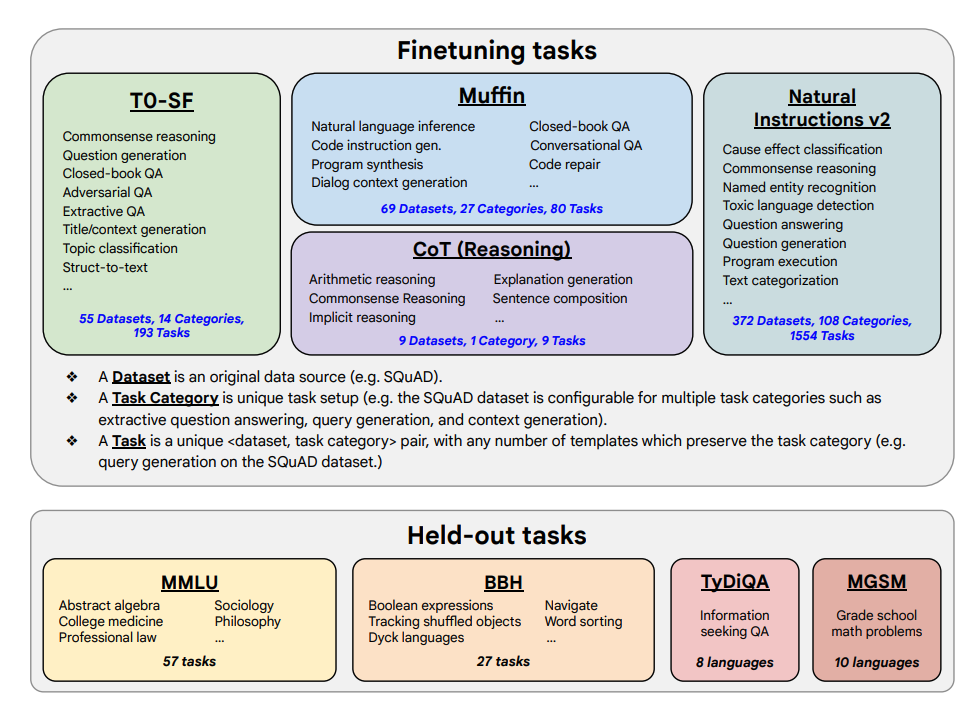
機能と主要結果
- 指示によるファインチューニングは、タスク数とモデルサイズの両方にスケーリングすることができます。これは、タスク数とモデルサイズのスケーリングがさらなるパフォーマンス向上の必要性を示唆しています。
- CoTデータセットをファインチューニングに追加することで、推論タスクにおいて良好なパフォーマンスを発揮することができます。
- Flan-PaLMは、多言語能力が向上しており、ワンショットTyDiQAで14.9%、未代表言語の算術推論で8.1%の改善が見られます。
- Plan-PaLMは、オープンエンドの生成問題に対しても良好なパフォーマンスを発揮するため、改善された利用性の指標となります。
- 責任あるAI(RAI)ベンチマーク全体でパフォーマンスが向上しています。
- Flan-T5の指示によるチューニングモデルは、強力なフューショット能力を示し、T5のパブリックチェックポイントなどを上回ります。
ファインチューニングタスク数とモデルサイズをスケーリングした場合の結果: モデルサイズとファインチューニングタスク数の両方をスケーリングすることにより、パフォーマンスが継続的に改善されると予想されますが、タスク数をスケーリングすることは収益が減少することがわかっています。
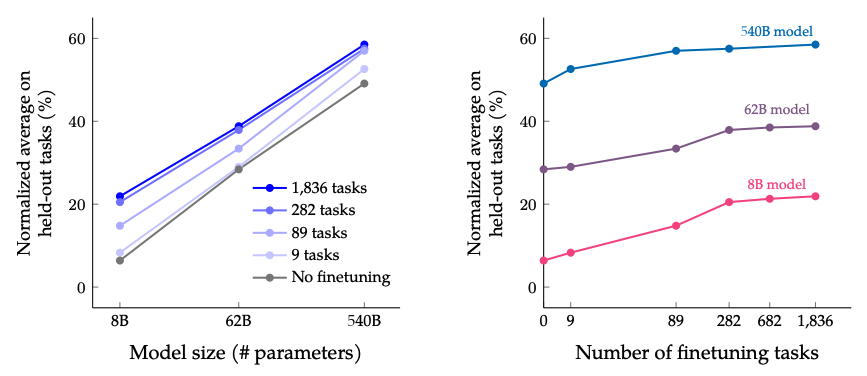
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
非CoTとCoTのデータでファインチューニングした場合の結果: 非CoTとCoTのデータの両方でファインチューニングを行うことで、単一の評価の場合よりも両方でパフォーマンスが向上します。
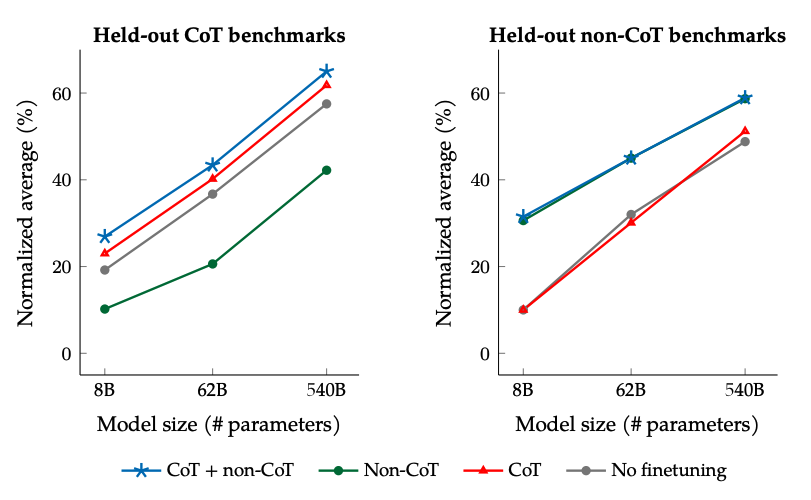
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
さらに、CoTと自己整合性を組み合わせることで、いくつかのベンチマークで最先端の結果を達成しています。 CoT +自己整合性は、数学問題を含むベンチマークにおいても結果を大幅に改善します(例:MGSM、GSM8K)。
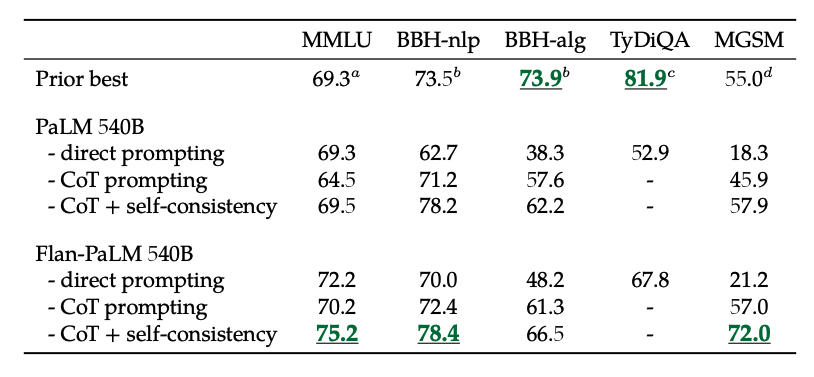
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
CoTファインチューニングは、BIG-Benchタスクの「一歩一歩考えてみましょう」というフレーズにより、ゼロショット推論が可能になります。一般的に、ファインチューニングなしのゼロショットCoT PaLMよりも、ゼロショットCoT Flan-PaLMの方が優れたパフォーマンスを発揮します。
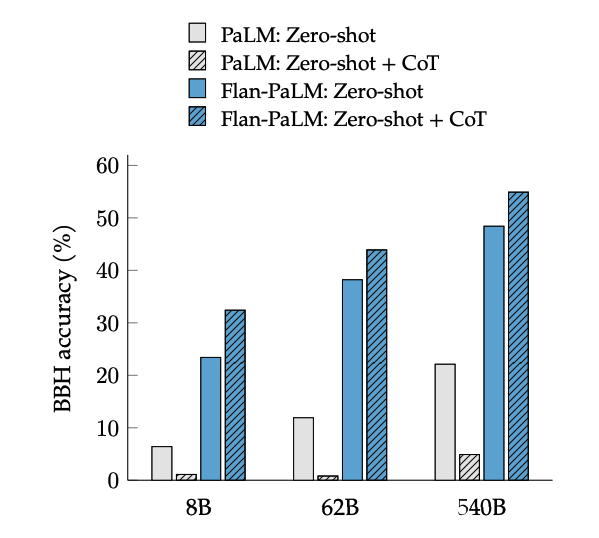
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
以下は、PaLMとFlan-PaLMのゼロショットCoTの見本です。
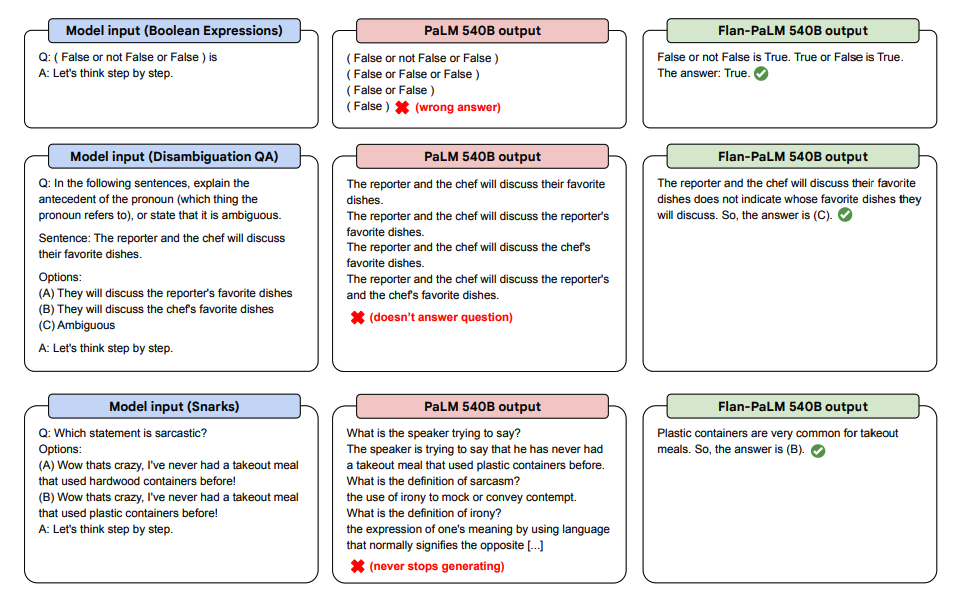
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
以下は、ゼロショットでのプロンプトの例です。PaLMモデルが、Flan-PaLMが良好なパフォーマンスを発揮できるZero-shot設定において、繰り返しに苦戦し、指示に対して返答しない様子を示しています。Few-shotの模範解答は、これらのエラーを軽減することができます。
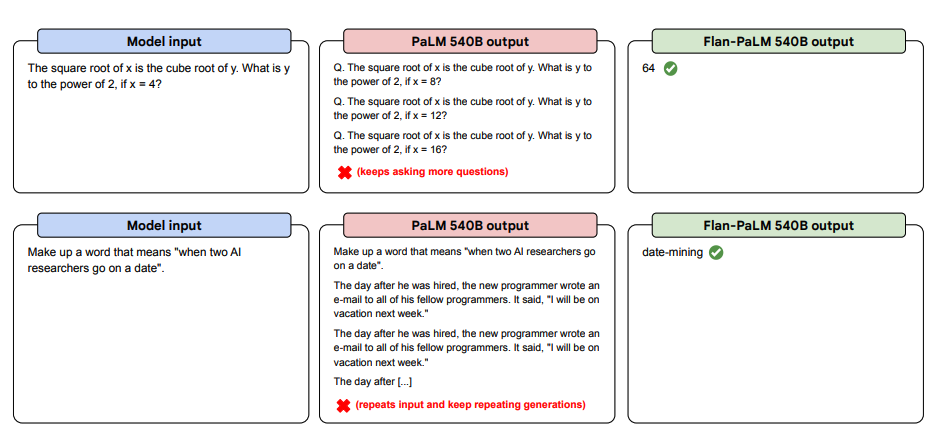
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
以下は、Flan-PALMモデルのゼロショット能力を、いくつかの異なるタイプの難しい自由形式の質問で実証した例です:
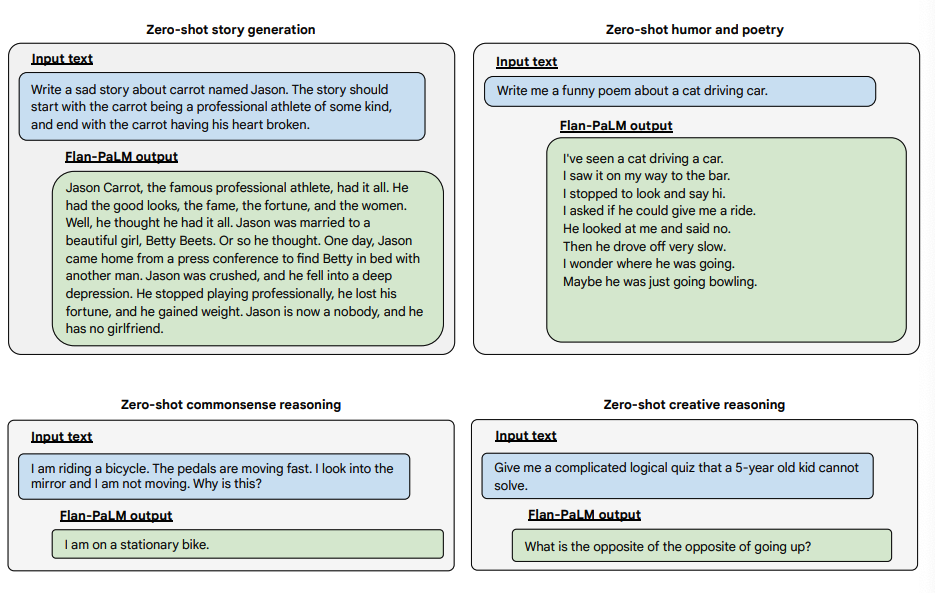
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
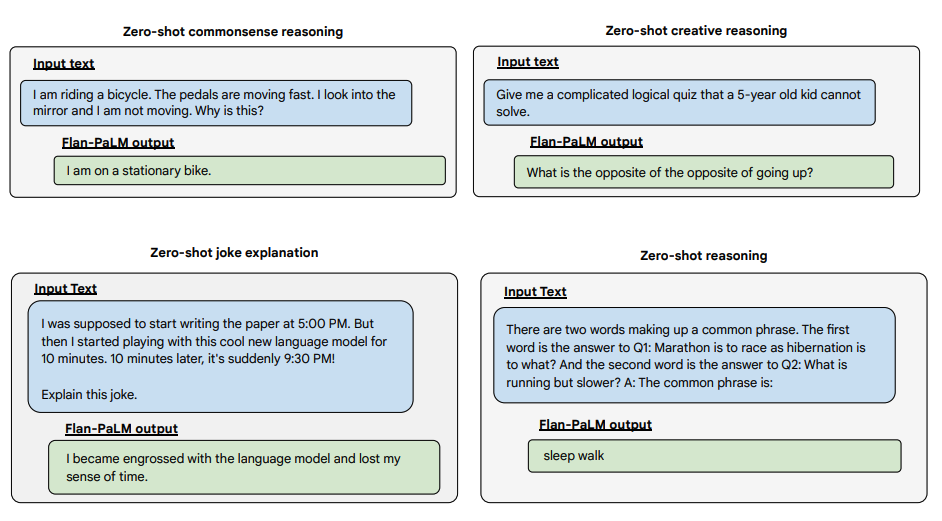
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
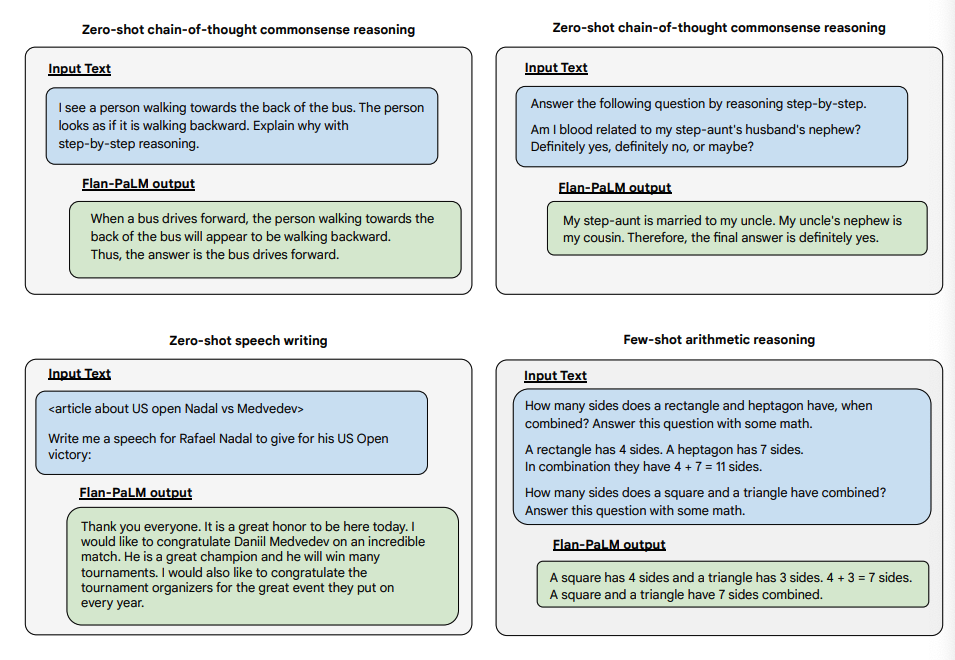
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)