Tree of Thoughts (ToT)
Для сложных задач, которые требуют исследования или стратегического планирования, традиционные или простые методы создания промптов оказываются недостаточными. Yao et el. (2023) (opens in a new tab) and Long (2023) (opens in a new tab) недавно предложили Tree of Thoughts (ToT), фреймворк, который обобщает метод цепочки мыслей и поощряет исследование мыслей, которые служат промежуточными шагами для общего решения проблем с помощью языковых моделей.
ToT поддерживает дерево мыслей, где мысли представляют собой последовательности связной речи, которые служат промежуточными шагами к решению проблемы. Этот подход позволяет лингвистической модели самооценить прогресс промежуточных мыслей в решении проблемы через обдуманный процесс рассуждения. Затем способность лингвистической модели генерировать и оценивать мысли объединяется с алгоритмами поиска (например, поиск в ширину и поиск в глубину), чтобы обеспечить систематическое исследование мыслей с опережением и возвратом назад.
Фреймворк ToT проиллюстрирован ниже:
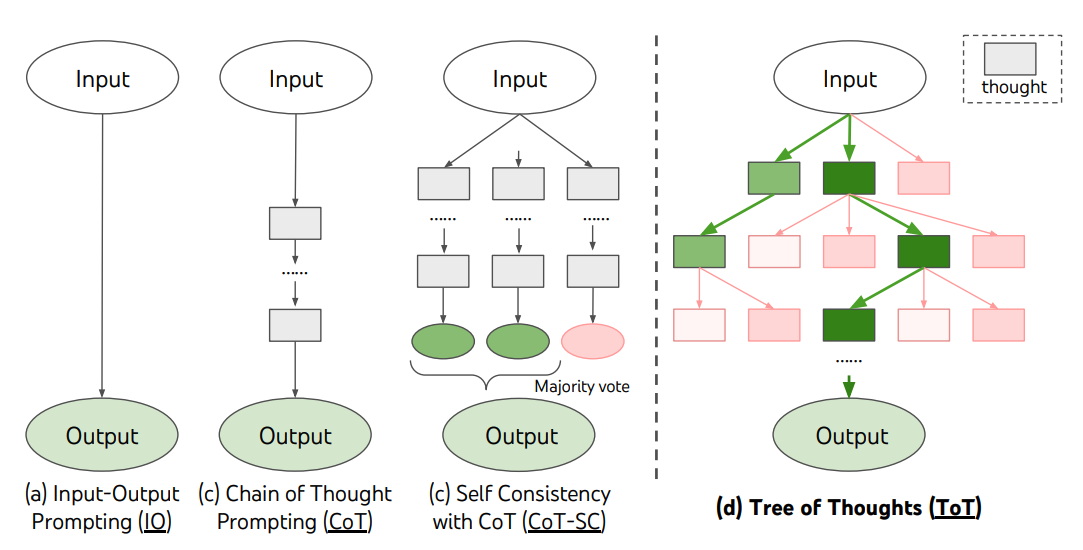
Image Source: Yao et el. (2023) (opens in a new tab)
"При использовании ToT различные задачи требуют определения количества кандидатов и количества мыслей/шагов. Например, как показано в статье, Игра в 24 используется в качестве задачи математического рассуждения, которая требует декомпозиции мыслей на 3 шага, каждый из которых включает промежуточное уравнение. На каждом шаге сохраняются лучшие b=5 кандидатов.
Чтобы выполнить BFS в ToT для задачи "Игра 24", ЛМ предлагается оценить каждую мысль кандидата как "уверен/может быть/невозможно" в отношении достижения 24. Как утверждают авторы, "цель состоит в том, чтобы продвигать правильные частичные решения, которые могут быть проверены в течение нескольких пробных попыток, исключить невозможные частичные решения, на основе “слишком большого/маленького” здравого смысла, и сохраненить остальные "возможно"". Значения выбираются 3 раза для каждой мысли. Процесс проиллюстрирован ниже:
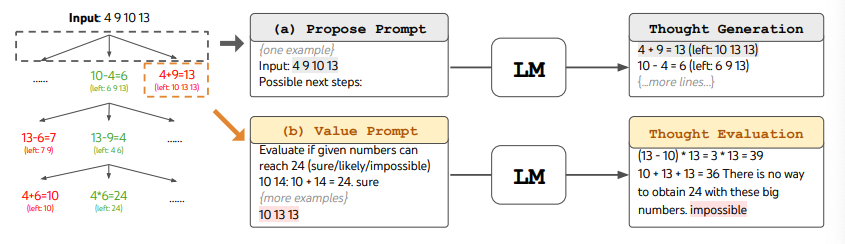
Image Source: Yao et el. (2023) (opens in a new tab)
Судя по результатам, представленным на рисунке ниже, ToT значительно превосходит другие методы промтинга:
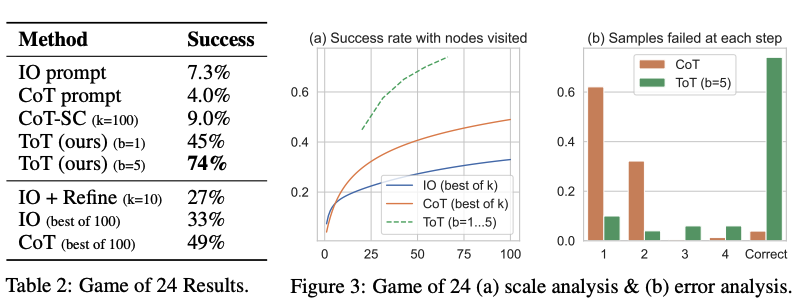
Image Source: Yao et el. (2023) (opens in a new tab)
Код доступен here (opens in a new tab) and here (opens in a new tab)
На высоком уровне основные идеи Yao et el. (2023) (opens in a new tab) и Long (2023) (opens in a new tab) схожи. Обе они расширяют возможности LLM для решения сложных задач путем поиска поиск по дереву с помощью многоэтапного диалога. Одно из основных различий заключается в том, что в Yao et el. (2023) (opens in a new tab) используется DFS/BFS/beam поиск, в то время как стратегия поиска по дереву (т.е. возвращаться назад, на сколько уровней и т.д.), предложенная в Long (2023) (opens in a new tab), управляется "контроллером ToT", обученным с помощью обучения с подкреплением. DFS/BFS/Beam search - это общие стратегии поиска решений без адаптации к конкретным задачам. Для сравнения, ToT-контроллер, обученный с помощью RL, может обучаться на новых наборах данных или в процессе самостоятельной игры (AlphaGo vs перебор), и, следовательно, система ToT на основе RL может продолжать развиваться и получать новые знания даже при фиксированной LLM.
Hulbert (2023) (opens in a new tab) предложила метод Tree-of-Thought Prompting, который применяет основную концепцию из ToT-фреймворков в качестве простой техники промтинга, где LLM оценивает промежуточные мысли в единственном промте. Пример:
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is...