LLaMA: Açık ve Verimli Temel Dil Modelleri
This section is under heavy development.
Yenilikler neler?
Bu makale, 7B'den 65B'ye kadar parametreleri olan temel dil modelleri koleksiyonunu tanıtır.
Modeller, genel olarak mevcut veri setleri ile trilyonlarca token üzerinde eğitilmiştir.
(Hoffman ve ark. 2022) (opens in a new tab) tarafından yapılan çalışma, daha küçük modellerin çok daha fazla veri üzerinde eğitilmesi durumunda, büyük modellerden daha iyi performans gösterebileceğini ortaya koydu. Bu çalışma, 10B modellerin 200B token üzerinde eğitilmesini önerir. Ancak, LLaMA makalesi, 7B modelin performansının 1T tokenin üzerine çıkmasının ardından bile gelişmeye devam ettiğini bulmuştur.
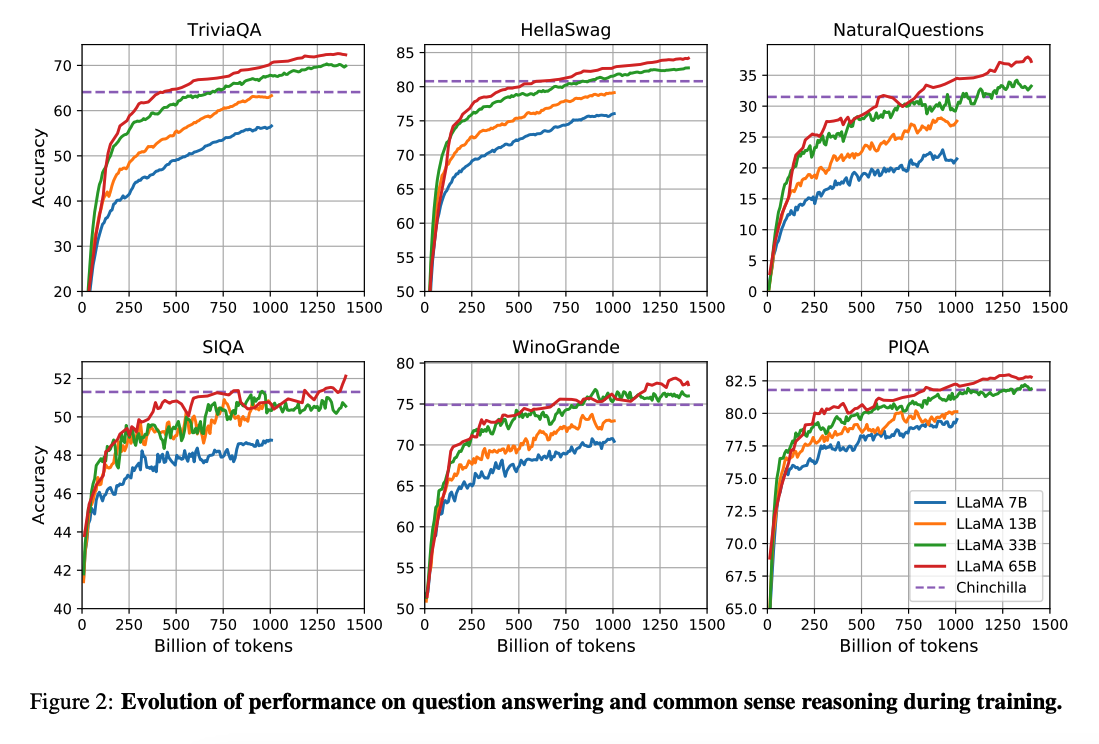
Bu çalışma, daha fazla token üzerinde eğitim yaparak, çeşitli çıkarım bütçelerinde olabilecek en iyi performansı elde eden modeller (LLaMA) üzerine odaklanmaktadır.
Yetenekler & Ana Sonuçlar
Genel olarak, LLaMA-13B, 10 kat daha küçük olmasına ve tek bir GPU'da çalıştırılabilmesine rağmen, birçok referans noktasında GPT-3(175B)'yu geride bırakır. LLaMA 65B, Chinchilla-70B ve PaLM-540B gibi modellerle rekabetçidir.
Makale: LLaMA: Açık ve Verimli Temel Dil Modelleri (opens in a new tab)
Kod: https://github.com/facebookresearch/llama (opens in a new tab)
Kaynaklar
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (March 2023)
- GPT4All (opens in a new tab) (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (March 2023)
- Stanford Alpaca (opens in a new tab) (March 2023)