LLaMA: Open and Efficient Foundation Language Models
Tämä osa sivustoa kehittyy jatkuvasti.
What's new?
Tämä julkaisu esittelee kokoelman peruskielimalleja, joiden koko vaihtelee 7 miljardista 65 miljardiin parametriin.
Mallit on koulutettu biljoonilla tokeneilla julkisesti saatavilla olevista tietojoukoista.
(Hoffman ym. 2022) (opens in a new tab) artikkelissa todetaan, että pienemmät kielimallit voivat saavuttaa paremman suorituskyvyn suuriin kielimalleihin verrattuna, kun pienemmälle kielimallille annetaan enemmän dataa, ja jos laskentaan käytettävä budjetti on rajallinen. Tämä tutkimus suosittelee 10B mallien kouluttamista 200B: tokenin datalla. LLaMA-julkaisussa havaitaan, että 7B mallin suorituskyky paranee edelleen jopa 1T (biljoonan) tokenin jälkeen.
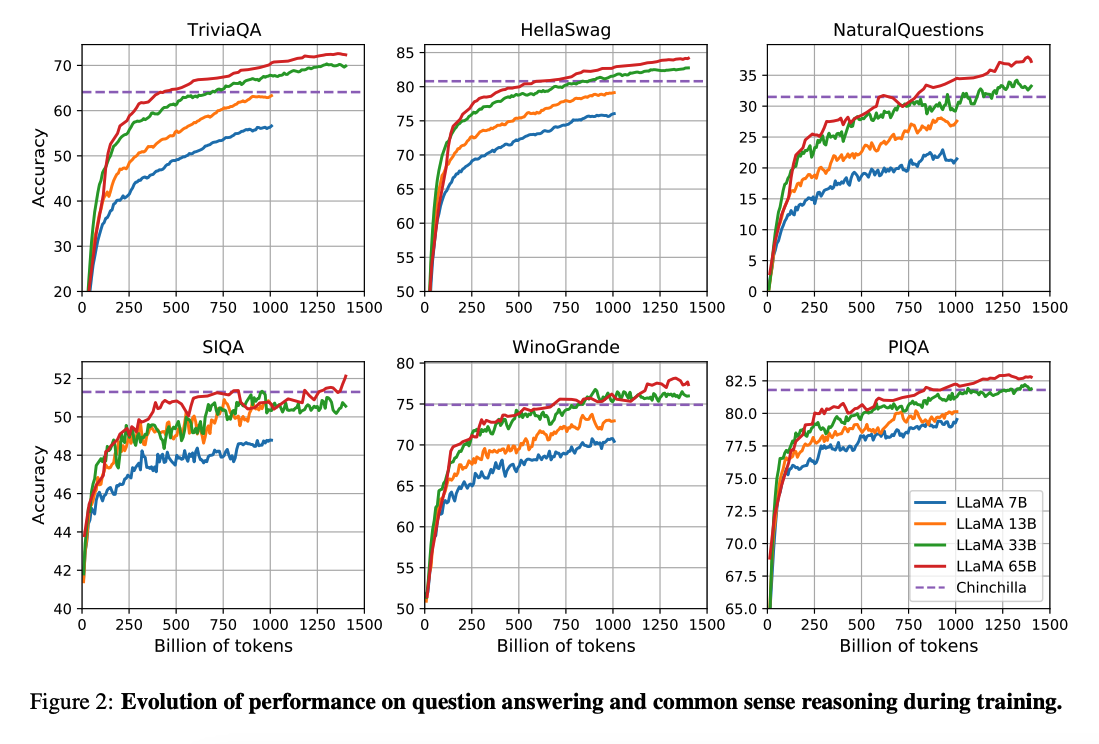
Tässä artikkelissa keskitytään LLaMA mallien kouluttamiseen, jotka saavuttavat parhaan mahdollisen suorituskyvyn ottaen huomioon erilaiset budjettirajoitteet, käyttämällä suurempaa määrää koulutustokeneja.
Kyvykkyydet ja keskeiset tulokset
Kaiken kaikkiaan LLaMA-13B suoriutuu GPT-3:a (175B) paremmin monissa vertailukohteista vaikka se on 10 kertaa pienempi ja mahdollista ajaa yhdellä GPU:lla. LLaMA 65B on kilpailukykyinen verrattuna malleihin kuten Chinchilla-70B ja PaLM-540B.
Julkaisu: LLaMA: Open and Efficient Foundation Language Models (opens in a new tab)
Koodi: https://github.com/facebookresearch/llama (opens in a new tab)
Viitteet
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (March 2023)
- GPT4All (opens in a new tab) (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (March 2023)
- Stanford Alpaca (opens in a new tab) (March 2023)