高效处理无限长文本的Transformer模型
Google的最新研究 (opens in a new tab)在标准的点积注意力机制中整合了压缩内存技术。
这项技术的目标是让Transformer大语言模型能够使用有限的内存足迹和计算资源,有效地处理长度几乎无限的输入数据。
研究团队提出了一种名为Infini-attention的新型注意力技术,它将一个压缩内存模块融入到了标准的注意力机制中。
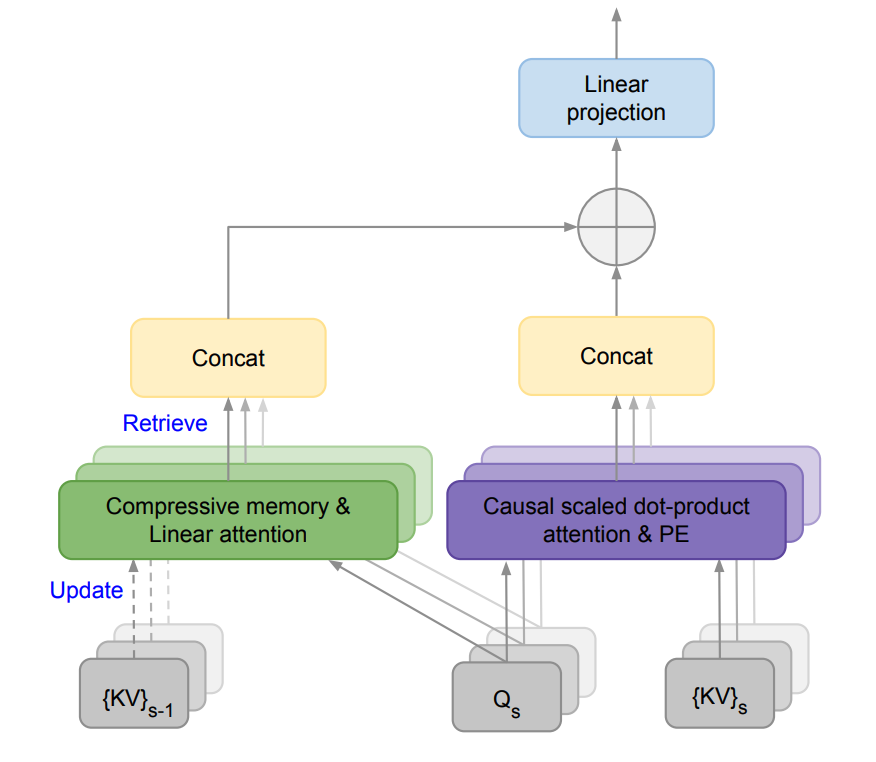
Infini-attention技术在单个Transformer模块中结合了局部掩蔽注意力和长期线性注意力,这使得Infini-Transformer模型能够高效地同时处理长距离和短距离的上下文依赖。
使用这种技术,模型在处理长文本的语言建模任务中,性能超越了现有的标准模型,内存使用量压缩了114倍。
研究还表明,一个拥有100亿参数的大语言模型可以轻松处理长度为100万的数据序列,而一个拥有800亿参数的模型在处理50万字符长度的书籍摘要任务上,取得了当前最佳的成绩。
随着处理长文本的大型语言模型变得越来越重要,通过高效的内存系统,这些模型将能更好地进行推理、规划和持续学习,展现出更加强大的问题处理能力。