LLaMA: 개방적이고 효율적인 기반 언어 모델(Foundation Language Models)
⚠️
이 섹션은 현재 개발중에 있습니다.
새로운 기능
이 논문은 70억개에서 650억개의 파라미터까지 다양한 사이즈의 기반 언어 모델(foundation language models)들을 소개합니다.
이 모델들은 공개된 데이터셋에서 조 단위 갯수의 토큰으로 학습되었습니다.
(Hoffman et al. 2022) (opens in a new tab)의 연구는 더 많은 데이터에서 학습된 작은 모델이 반대 경우의 더 큰 모델보다 나은 성능을 발휘할 수 있다는 것을 보여줍니다. 이 연구에서는 2000억개 토큰에서 100억개 모델을 학습하는 것을 권장하고 있습니다. 그러나 LLaMA 논문에서는 70억개 모델의 성능은 1조개의 토큰 이후에도 지속해서 향상된다는 것을 발견했습니다.
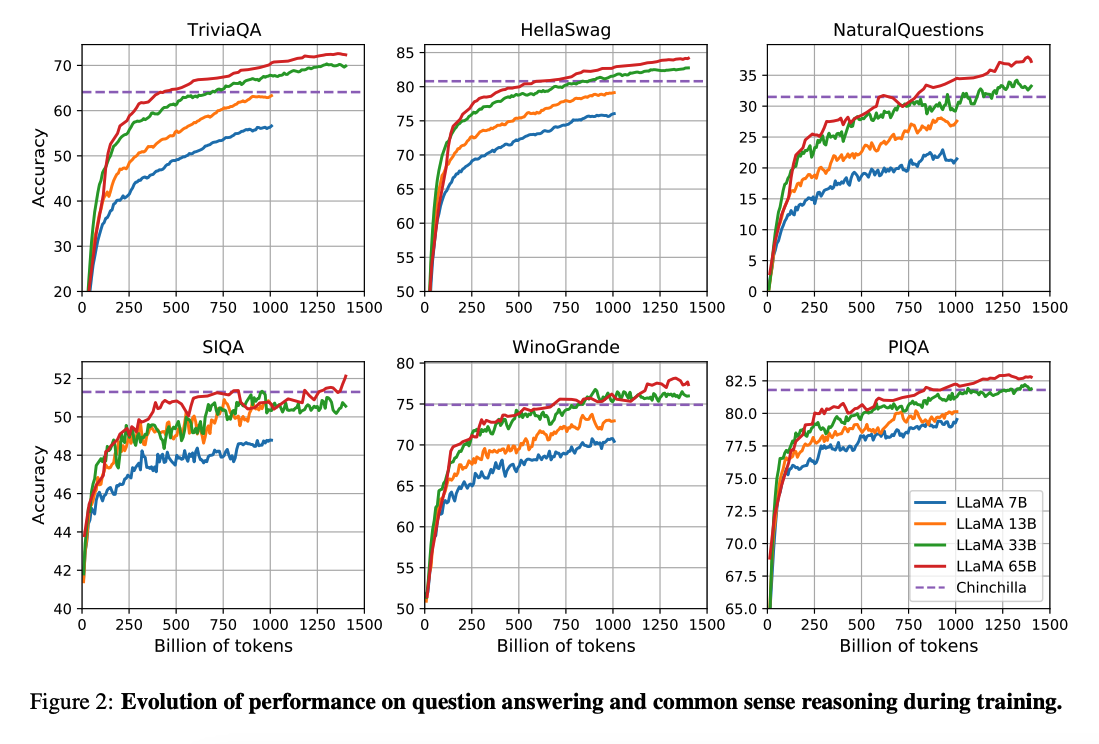
이 논문은 다양한 추론 환경에서 더 많은 토큰으로 학습함으로써, 최상의 성능을 달성하는 모델(LLaMA)을 학습하는 데 초점을 맞추고 있습니다.
능력 & 주요 결과
전반적으로, LLaMA-13B는 GPT-3(175B)보다 10배 작지만 다양한 벤치마크에서 더 나은 성능을 보이며, 단일 GPU에서도 작동이 가능합니다. LLaMA 65B는 Chinchilla-70B 및 PaLM-540B 같은 모델들과 경쟁력이 있습니다.
논문: LLaMA: Open and Efficient Foundation Language Models (opens in a new tab)
코드: https://github.com/facebookresearch/llama (opens in a new tab)
참고자료 (References)
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (March 2023)
- GPT4All (opens in a new tab) (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (March 2023)
- Stanford Alpaca (opens in a new tab) (March 2023)