ReAct Prompting
Yao et al., 2022 (opens in a new tab)에서는 대규모언어모델을 사용하여 추론 추적과 작업별 행동을 인터리브 방식으로 생성하는 ReAct라는 프레임워크를 소개했습니다.
추론 추적을 생성하면 모델이 행동 계획을 유도, 추적, 업데이트하고 예외를 처리할 수 있습니다. 행동 단계(action step)에서는 지식 기반이나 환경과 같은 외부 소스와 상호 작용하고 정보를 수집할 수 있습니다.
ReAct 프레임워크를 사용하면 대규모언어모델이 외부 도구와 상호 작용하여 보다 신뢰할 수 있고 사실적인 응답으로 이어지는 추가 정보를 검색할 수 있습니다.
연구 결과에 따르면 ReAct는 언어 및 의사 결정 작업에서 여러 최신 기술의 기준선을 능가할 수 있는 것으로 나타났습니다. 또한 ReAct는 인간의 해석 가능성과 대규모언어모델의 신뢰성을 향상시킵니다. 전반적으로 저자들은 추론 과정에서 얻은 내부 지식과 외부 정보를 모두 사용할 수 있는 생각의 사고(CoT)와 함께 ReAct를 사용하는 것이 가장 좋은 접근 방식이라는 사실을 발견했습니다.
How it Works?
ReAct는 인간이 새로운 작업을 학습하고 의사 결정이나 추론을 할 수 있도록 하는 "행동" 과 "추론"의 시너지 효과에서 영감을 받았습니다.
생각의 사고(CoT) 프롬프팅은 다른 작업들 중에 산술 및 상식적 추론과 관련된 질문에 대한 답을 생성하기 위해 추론 추적을 수행하는 대규모언어모델의 능력을 보여주었습니다(Wei et al., 2022) (opens in a new tab). 그러나 외부 세계에 대한 접근성이 부족하거나 지식을 업데이트하는 능력이 부족하면 사실 착각(fact hallucination)이나 오류 전파 같은 문제가 발생할 수 있습니다.
ReAct는 추론과 행동을 대규모언어모델과 결합하는 일반적인 패러다임입니다. ReAct는 대규모언어모델이 작업을 위해 언어 추론 추적과 행동을 생성하도록 유도합니다. 이를 통해 시스템은 행동에 대한 계획을 생성, 유지 및 조정하는 동시에 외부 환경(예: Wikipedia)과의 상호 작용을 통해 추론에 추가 정보를 통합할 수 있습니다. 아래 그림은 ReAct의 예와 질문 답변을 수행하는데 필요한 다른 단계들을 보여줍니다.

이미지 출처: Yao et al., 2022 (opens in a new tab)
위의 예에서, 우리는 HotpotQA (opens in a new tab)에서 아래 질문과 같은 프롬프트를 전달합니다.
Apple Remote 외에 Apple Remote가 원래 상호 작용하도록 설계된 프로그램을 제어할 수 있는 다른 장치는 어떤 것이 있니?문맥 내(in-context) 예시는 프롬프트에 추가되지만, 여기에서는 단순화를 위해 제외됨을 유의하세요. 우리는 모델이 작업 해결 궤적(생각, 행동)을 생성하는 것을 볼 수 있습니다. Obs는 상호작용 중인 환경(예: 검색 엔진)에서의 관찰에 해당합니다. 본질적으로, ReAct는 추론을 지원하기 위해 정보를 검색할 수 있으면, 추론은 다음에 검색할 대상을 타겟팅하는데 도움이 됩니다.
ReAct Prompting
ReAct 프롬프팅이 어떻게 작동하는지 설명하기 위해, 논문에서 예시를 살펴보겠습니다.
첫 번째 단계는 트레이닝 세트(예:HotPotQA)에서 사례를 선택하고 ReAct 형식의 궤적을 구성하는 것입니다. 이것들은 프롬프트에서 퓨샷(few-shot) 견본으로 사용됩니다. 궤적은 위 그림과 같이 여러 생각-행동-관찰 단계로 구성됩니다. 자유 형태 사고는 질문 분해, 정보 추출, 상식/산술적 추론 수행, 검색 공식화 안내, 그리고 최종 답변 합성과 같은 다른 작업들을 수행하는데 사용됩니다.
다음은 ReAct 프롬프트 모범 예시입니다(논문에서 가지고 온 것으로, 간결하게 하기 위해 하나의 예로 줄였습니다).
질문 콜로라도 조산 운동의 동쪽 구역이 확장되는 지역의 표고 범위는 얼마이니?
생각 1 콜로라도 조산 운동을 검색하여, 콜로라도 조산 운동의 동쪽 구역이 확장되는 지역을 찾은 다음, 그 지역의 표고 범위를 찾아야 해.
행동 1 검색하기[콜로라도 조산 운동]
관찰 1 콜로라도 조산 운동은 콜로라도와 그 주변 지역에서 산이 형성되는 과정(조산 운동)을 말해.
생각 2 동부에 대한 언급이 없어. 그래서 동부 섹터를 찾아봐야겠어.
행동 2 찾아보기[동부 섹터]
관찰 2 (결과 1 / 1) 동쪽 섹터는 고원 지대까지 뻗어 있고 중앙 평원 조산 운동이라고 불려.
생각 3 콜로라도 조산 운동의 동쪽 섹터는 고원 지대까지 뻗어 있어. 따라서 고원 지대를 검색하여 해발 범위를 찾아야 해.
행동 3 검색[고원 지대]
관찰 3 고원 지대는 두 개의 다른 지대 중 하나를 가르켜.
생각 4 대신 고원 지대(미국)를 검색해야해.
행동 4 검색[고원 지대 (미국)]
관찰 4 고원 지대는 대평원\(the Great Plains\)의 일부 지역이야. 동쪽에서 서쪽으로, 고원 지대는 약 1,800피트에서 7,000피트(550~2,130m)까지 고도가 높아져.[3]
생각 5 고원 지대의 해발 고도는 약 1,800~7,000피트이므로, 정답은 1,800~7,000피트야.
행동 5 완료[1,800~7,000피트]
...다른 형태의 작업을 위해서는 다른 프롬프트가 사용되는 것에 유의하세요. 추론이 가장 중요한 작업(예: HotpotQA)의 경우, 작업 해결 궤적에 여러 생각-행동-관찰 단계가 사용됩니다. 많은 행동 단계가 포함되는 의사 결정의 경우, 생각은 드물게 사용됩니다.
Results on Knowledge-Intensive Tasks
이 논문에서는 먼저 질문 답변(HotPotQA) 그리고 사실 확인(Fever (opens in a new tab))과 같은 지식 집약적 추론 작업에 대해 ReAct를 평가합니다. PaLM-540B를 프롬프팅을 위한 기본 모델로 사용하였습니다.
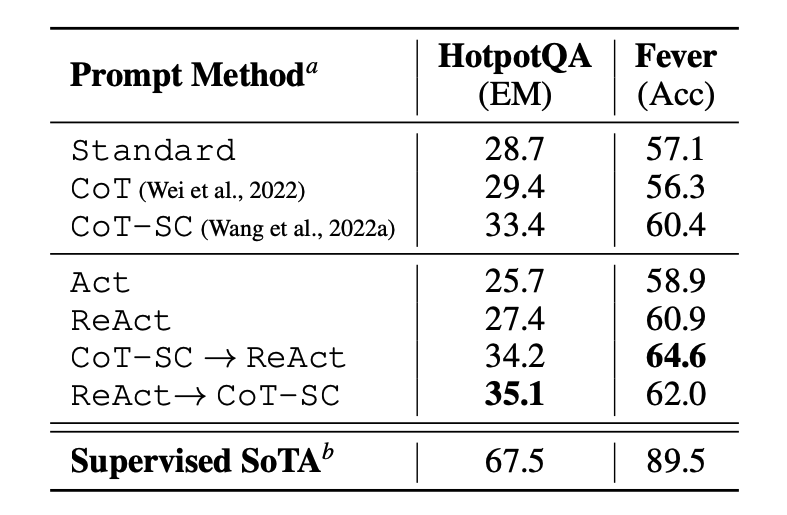
이미지 출처: Yao et al., 2022 (opens in a new tab)
서로 다른 프롬프팅 방법을 사용하는 HotPotQA와 Fever에 대한 프롬프팅 결과를 보면 일반적으로 두 작업 모두에서 ReAct가 Act(행동만 포함)보다 더 나은 성능을 보입니다.
또한 ReAct가 Fever에서는 CoT보다 성능이 뛰어나고 HotPotQA에서는 CoT보다 뒤처지는 것을 관찰할 수 있습니다. 자세한 오류 분석은 논문에서 확인할 수 있습니다. 요약하자면 다음과 같습니다.
- CoT 는 사실 착각에 시달립니다.
- ReAct의 구조적 제약은 추론 단계를 공식화할 때 유연성이 떨어집니다.
- ReAct는 검색하는 정보에 크게 의존합니다; 정보가 없는 검색 결과는 모델 추론을 방해하고 생각을 복구하고 재구성하는데 어려움을 초래합니다.
ReAct와 CoT+Self-Consistency 간의 전환을 결합하고 지원하는 프롬프팅 방법은 일반적으로 모든 다른 프롬프팅 방법들보다 성능이 뛰어납니다.
Results on Decision Making Tasks
이 논문에서는 의사 결정 작업에서 ReAct의 성능을 입증하는 결과도 보고합니다. ReAct는 ALFWorld (opens in a new tab)(텍스트 기반 게임)와 WebShop (opens in a new tab)(온라인 쇼핑 웹사이트 환경)이라는 두 가지 벤치마크에서 평가되었습니다. 두 벤치마크 모두 효과적으로 행동하고 탐색하기 위해 추론이 필요한 복잡한 환경을 포함합니다.
ReAct 프롬프트는 추론과 행동의 결합이라는 동일하 핵심 아이디어를 유지하면서 이러한 작업들에 대해 다르게 설계되었습니다. 아래는 ReAct 프롬프팅이 포함된 ALFWorld 문제의 예시입니다.
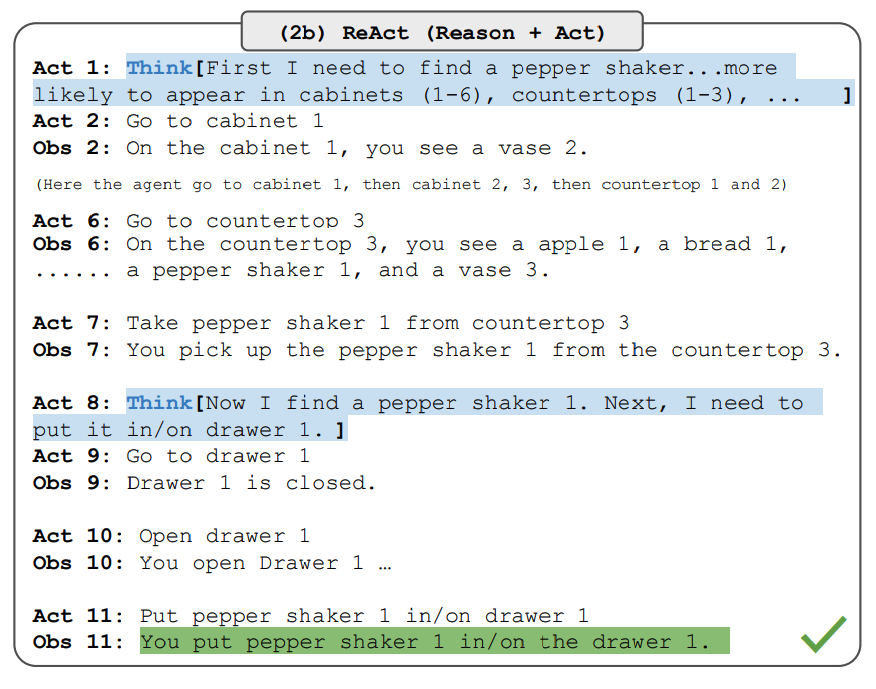
이미지 출처: Yao et al., 2022 (opens in a new tab)
ReAct는 ALFWorld와 Webshop 모두에서 Act 보다 성능이 뛰어납니다. 어떠한 생각이 없는 Act는 목표를 하위 목표로 정확하게 분해하는데 실패하였습니다. 추론은 이러한 유형의 작업에 대해 ReAct에서 이점이 있는 것으로 보이지만, 현재 프롬프팅 기반 방법은 여전히 이러한 작업들에 대한 전문 인력의 성능에는 미치지 못 합니다.
LangChain ReAct Usage
아래는 ReAct 프롬프팅 접근 방식이 실제로 어떻게 이루어지는지에 대한 개략적인 예입니다. 우리는 대규모언어모델과 다른 도구의 힘을 결합하여 작업을 수행하는 에이전트를 구축하기 위해 ReAct 프레임워크를 활용하는 기능이 이미 내장되어 있기 때문에 대규모언어모델과 LangChain (opens in a new tab)에 대해 OpenAI를 사용합니다.
먼저 필요한 라이브러리를 설치하고 가지고 옵니다.
%%capture
# update or install the necessary libraries
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# import libraries
import openai
import os
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# load API keys; you will need to obtain these if you haven't yet
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
이제 우리는 대규모언어모델, 우리가 사용할 도구들, 그리고 ReAct 프레임워크를 대규모언어모델과 도구를 함께 활용할 수 있는 에이전트를 구성할 수 있습니다. 외부 정보 검색하기 위한 검색 API와 수학 도구로는 대규모언어모델을 사용하는 것에 유의하세요.
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)구성이 완료되면, 우리는 이제 원하는 쿼리/프롬프트로 에이전트를 실행할 수 있습니다. 여기서는 백서에서 설명하는 것처럼 퓨샷 견본을 제공하지 않는다는 점에 유의하세요.
agent.run("Olivia Wilde의 남자 친구는 누구이니? 0.23 거듭제곱을 하면 현재 그의 나이는 얼마이니?")체인 실행(chain execution)은 다음과 같습니다.
> Entering new AgentExecutor chain...
나는 Olivia Wilde의 남자 친구가 누구인지 알아내고 0.23 거듭제곱을 한 그의 나이를 계산해야해.
행동 : 검색
행동 입력 : "Olivia Wilde 남자 친구"
관찰 : Olivia Wilde는 Jason Sudeikis와 수년간의 약혼을 끝낸 후 Harry Styles와 사귀기 시작했어. (두 사람간의 관계 타임라인 참조)
생각 : Harry Styles의 나이를 알아야해.
행동 : 검색
행동 입력 : "Harry Styles 나이"
관찰 : 29 세
생각 : 나는 29 에 0.23 거듭제곱을 계산해야 해.
행동 : 계산기
행동 입력 : 29^0.23
관찰 : 답변 : 2.169459462491557
생각 : 나는 이제 마지막 답변을 알고 있어.
최종 답변 : Olivia Wilde의 남자 친구인 Harry Styles는 29 세이고, 그의 나이에 0.23 거듭제곱한 값은 2.169459462491557 이야.
> Finished chain.출력은 다음과 같습니다.
"Olivia Wilde의 남자 친구인 Harry Styles는 29 세이고, 그의 나이에 0.23 거듭제곱한 값은 2.169459462491557 이야."이 예제는 LangChain 문서 (opens in a new tab)에서 가져온 것이므로 해당 문서에 공로가 있습니다. 우리는 학습자가 다양한 도구와 작업의 조합을 탐색해 볼 것을 권장합니다.
이 코드에 대한 노트북은 이곳 (opens in a new tab)에서 확인할 수 있습니다.