Reflexion
Reflexion은 언어 피드백을 통해 언어 기반 에이전트를 강화하는 프레임워크입니다. Shinn et al. (2023) (opens in a new tab)에 따르면, "Reflexion은 LLM 매개변수의 선택과 쌍을 이루는 에이전트의 메모리 인코딩으로 정책을 매개변수화하여 이루어 낸 '언어적' 강화 패러다임입니다."
고차원적으로, Reflexion은 환경 피드백(free-form language 또는 scalar)을 자기 성찰이라고도 하는 언어 피드백으로 변환합니다. 이는 다음 에피소드에서 LLM 에이전트의 컨텍스트로 제공합니다. 이 과정을 통해 에이전트는 이전의 실수로부터 빠르고 효과적으로 학습하여 다양하고 어려운 작업의 성능을 향상시킵니다.
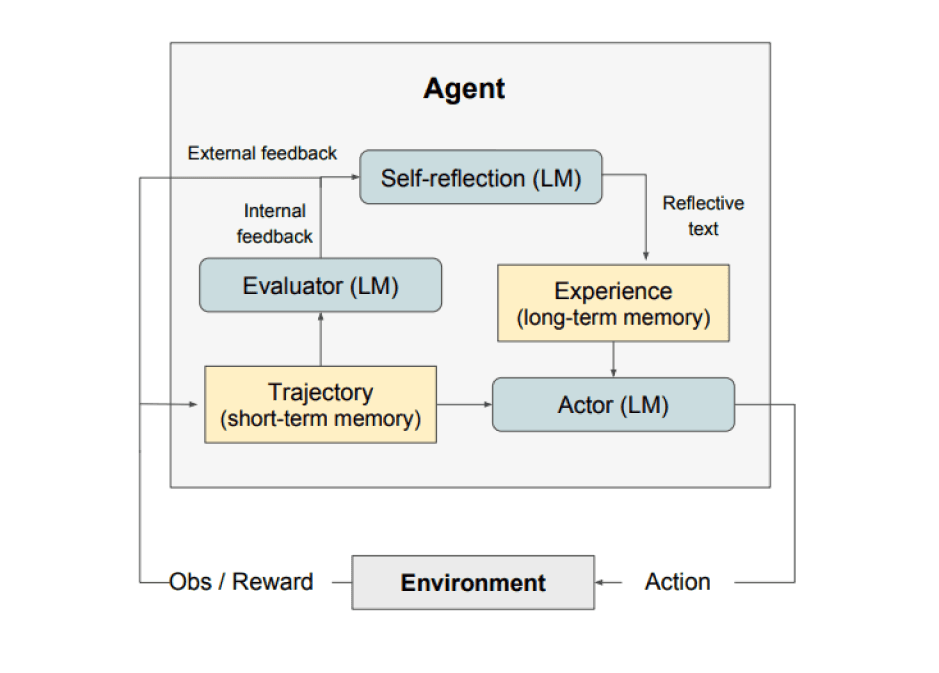
위 그림처럼 Reflection은 세 가지 모델로 구성되어 있습니다:
- An Actor: 상태 관찰을 기반으로 텍스트와 액션을 생성합니다. Actor는 특정 환경에서 동작을 수행하고 궤적을 남기는 관찰의 대상입니다. 생각의 사슬 (Chain-of-Thought) (opens in a new tab)과 ReAct (opens in a new tab)는 Actor 모델을 생성합니다. 또한 에이전트에 추가 컨텍스트를 제공하기 위해 메모리 구성 요소가 추가됩니다.
- An Evaluator: Actor가 산출한 점수입니다. 명확하게 말하자면, 단기 기억이라고도 불리는 생성 궤적을 인풋으로 입력 받으면 보상 점수(reward score)를 아웃풋으로 산출하는 방식입니다. 작업에 따라 상이한 보상 기능이 작동합니다. (LLM과 규칙 기반 휴리스틱은 의사 결정 작업에 사용됩니다)
- 자기성찰(Self-Reflection): Actor의 자기계발을 돕기 위한 언어적 강화 단서를 생성합니다. 이 역할은 LLM에 의해 달성되며 추후 시행(trial)을 위한 중요한 피드백을 제공합니다. 자기성찰모델(Self-Reflection Model)은 보상 신호, 현재 궤적과 지속적인 메모리를 통해 관련 피드백을 생성하고 이를 메모리에 저장합니다. 에이전트는 이러한 경험(장기 기억 저장)을 활용하여 의사 결정을 신속하게 개선합니다.
요약하자면, Reflection 프로세스의 주요 단계는 a) 작업을 정의하고, b) 궤적을 생성하고, c) 평가하고, d) 성찰(reflection)을 수행하고, e) 다음 궤적을 생성합니다. Reflection 에이전트가 의사 결정, 프로그래밍 또는 추론과 같은 다양한 작업을 해결하기 위한 반복적 행동을 최적화하는 방법을 배우는 예시를 아래의 그림을 통해 볼 수 있습니다. Reflection은 자기 평가(self-evaluation), 자기 성찰(self-reflection) 및 메모리 컴포넌트를 도입하여 ReAct 프레임워크를 확장합니다.
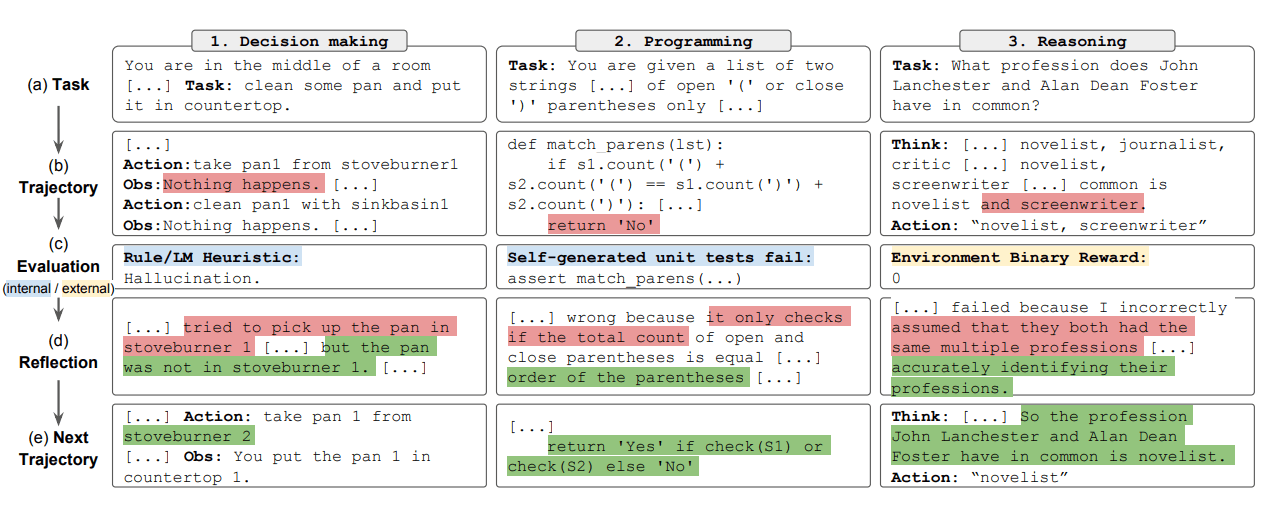
결과
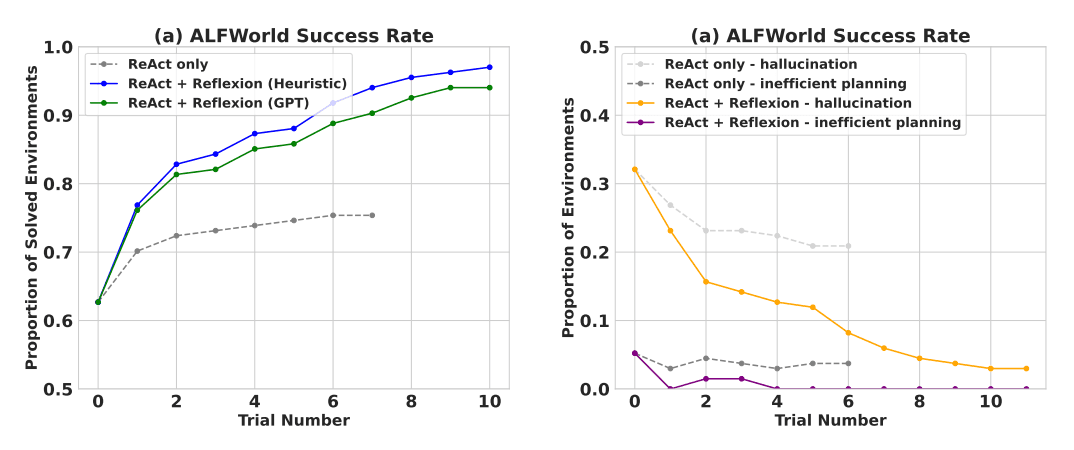
실험 결과에 따르면 Reflexion 에이전트는 의사 결정 AlfWorld 작업, HotPotQA의 추론 질문 및 HumanEval의 Python 프로그래밍 작업에서 성능을 크게 향상시키는 것으로 나타났습니다.
순차적 의사 결정(AlfWorld) 작업 평가 부문에서, ReAct + Reflexion은 이진 분류를 위해 휴리스틱 및 GPT의 자체 평가 기법을 사용하여 총 134개 중 130의 작업을 완료함으로써 ReAct를 크게 능가함을 증명합니다.
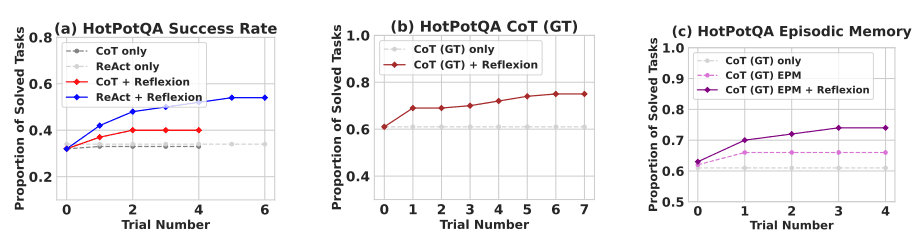
Reflexion 여러 학습 단계에 걸쳐 모든 베이스라인을 크게 능가합니다. 오로지 추론의 경우 그리고 가장 최신 궤적으로 구성된 에피소드 메모리를 추가할 때 Reflexion + CoT는 그 에피소드 메모리를 가진 CoT 그 자신과 CoT를 각각 능가합니다.
아래 표에 요약된 바와 같이 Reflexion은 MBPP, HumanEval 및 Leetcode Hard에서 Python 및 Rust 코드 작성에 대한 이전의 최첨단 접근 방식을 손쉽게 능가합니다.

언제 Reflexion을 써야할까요?
Reflexion은 다음과 같은 항목에 적합합니다:
- 에이전트는 시행착오를 통해 배웁니다: Reflection은 에이전트가 과거의 실수를 반성하고 그 지식을 미래의 결정에 통합함으로써 성능을 향상시키도록 설계되었습니다. 따라서 의사 결정, 추론 및 프로그래밍과 같이 에이전트가 시행착오를 통해 학습해야 하는 작업에 적합합니다.
- 전통적인 강화 학습 방법은 비현실적입니다: 전통적인 강화 학습(Reinforcement Learning)방식은 광범위한 훈련 데이터와 값비싼 모델 미세 조정(fine-tuning)이 필요한 경우가 많습니다. Reflection은 기본 언어 모델을 미세 조정(fine-tuning)할 필요가 없는 손쉬운 대안을 제공하므로 데이터 및 컴퓨팅 리소스 측면에서 더 효율적입니다.
- 어감에 따른 피드백이 필요합니다: Reflexion은 언어 피드백을 활용하며, 이는 기존 강화 학습(Reinforcement Learning)에서 사용되는 scalar 보상보다 더 미묘하고 구체적일 수 있습니다. 이를 통해 에이전트는 실수를 더 잘 이해하고 추후 시험에서 개선된 목표에 한 발짝 더 다가설 수 있습니다.
- 해석 가능성(Interpretability)과 명시적 기억이 중요합니다: Reflexion은 기존 강화 학습(Reinforcement Learning) 방법에 비해 더 해석 가능하고 명시적인 형태의 에피소드 메모리를 제공합니다. 에이전트의 자기 성찰(self-reflection)은 메모리에 저장되어 학습 과정을 더 쉽게 분석하고 이해할 수 있습니다.
Reflexion은 다음과 같은 항목에 효과적입니다:
- 순차적 의사결정: Reflexion 에이전트는 다양한 환경을 탐색하고 여러 단계의 목표를 달성하는 것을 포함하는 AlfWorld 작업에서 성능을 향상시킵니다.
- Reasoning: Reflexion은 여러 문서에 대한 추론이 필요한 질의응답 데이터 세트인 HotPotQA에서 에이전트의 성능을 향상시켰습니다.
- 프로그래밍: Reflexion 에이전트는 HumanEval 및 MBPP와 같은 벤치마크에 더 나은 코드를 작성하여 경우에 따라 최첨단 결과를 달성합니다.
Reflection의 몇 가지 한계점은 다음과 같습니다:
- 자기평가(self-evaluation) 역량 의존: Reflection은 에이전트가 자신의 성과를 정확하게 평가하고 유용한 자기반성(self-reflection)을 생성하는 능력에 의존합니다. 이는 특히 복잡한 작업의 경우 어려울 수 있지만, 모델의 기능이 계속 향상됨에 따라 Reflexion이 시간이 지남에 따라 개선될 것으로 예상됩니다.
- 장기기억제약: Reflexion은 최대 용량의 슬라이딩 윈도우를 사용하지만 벡터 임베딩이나 SQL 데이터베이스와 같은 상대적으로 더 복잡한 작업의 경우 고급 구조(advanced structures)를 사용하는 것이 유리할 수 있습니다.
- 코드 생성 제한: 정확한 입출력 매핑(예: 하드웨어의 영향을 받는 비결정론적 생성기 함수 및 함수 출력)을 지정하는 데 테스트 주도 개발(test-driven development)에 제한이 있습니다.
Figures 출처: Reflexion: Language Agents with Verbal Reinforcement Learning (opens in a new tab)