LLaMA: Modelos de linguagem de base abertos e eficientes
Esta seção está em desenvolvimento intenso.
O que há de novo?
Este artigo apresenta uma coleção de modelos de linguagem de fundação que variam de parâmetros 7B a 65B.
Os modelos são treinados em trilhões de tokens com conjuntos de dados disponíveis publicamente.
O trabalho de (Hoffman et al. 2022) (opens in a new tab) mostra que, dado um orçamento de computação, modelos menores treinados em muito mais dados podem alcançar um desempenho melhor do que as contrapartes maiores. Este trabalho recomenda treinar modelos 10B em tokens 200B. No entanto, o artigo da LLaMA descobriu que o desempenho de um modelo 7B continua a melhorar mesmo após tokens 1T.
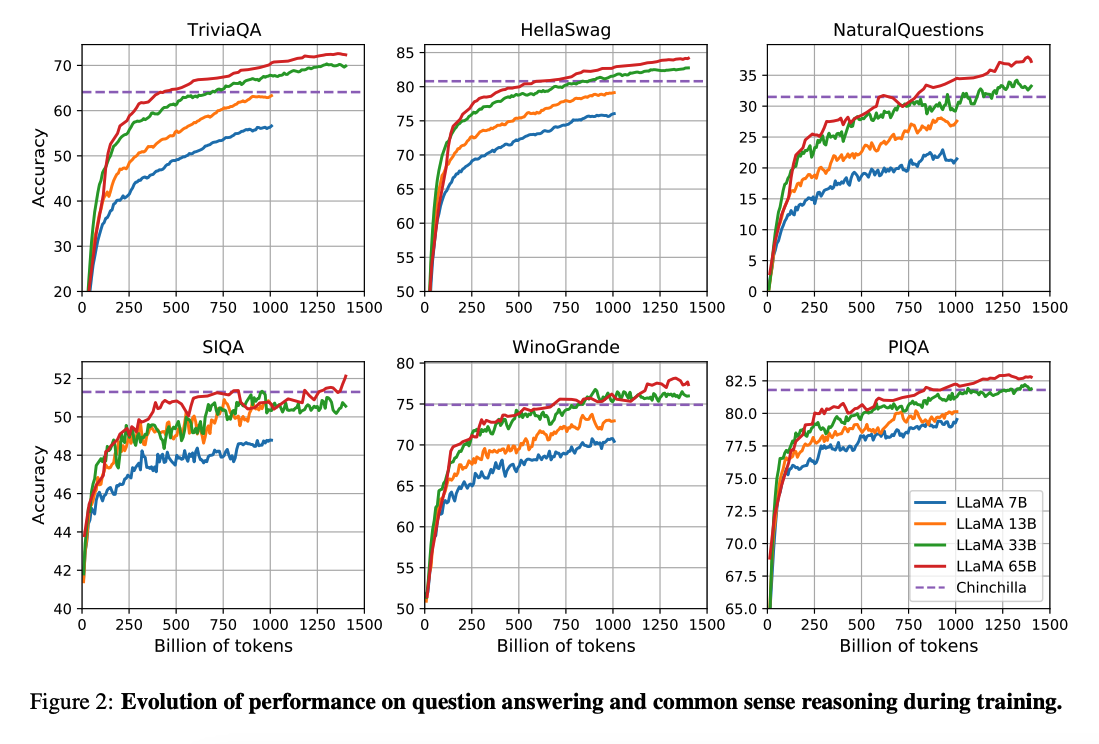
Este trabalho foca em modelos de treinamento (LLaMA) que alcançam o melhor desempenho possível em vários orçamentos de inferência, treinando em mais tokens.
Capacidades e Principais Resultados
No geral, o LLaMA-13B supera o GPT-3(175B) em muitos benchmarks, apesar de ser 10 vezes menor e possível de executar uma única GPU. O LLaMA 65B é competitivo com modelos como Chinchilla-70B e PaLM-540B.
Papel: LLaMA: Open and Efficient Foundation Language Models (opens in a new tab)
Código: https://github.com/facebookresearch/llama (opens in a new tab)
Referências
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (March 2023)
- GPT4All (opens in a new tab) (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (March 2023)
- Stanford Alpaca (opens in a new tab) (March 2023)