Prompt CoT Multimodal
Zhang et ai. (2023) (opens in a new tab) propôs recentemente uma abordagem de solicitação de cadeia de pensamento multimodal. O CoT tradicional foca na modalidade de linguagem. Em contraste, o Multimodal CoT incorpora texto e visão em uma estrutura de dois estágios. A primeira etapa envolve a geração de raciocínio com base em informações multimodais. Isso é seguido pela segunda fase, inferência de respostas, que aproveita os fundamentos informativos gerados.
O modelo CoT multimodal (1B) supera o GPT-3.5 no benchmark ScienceQA.
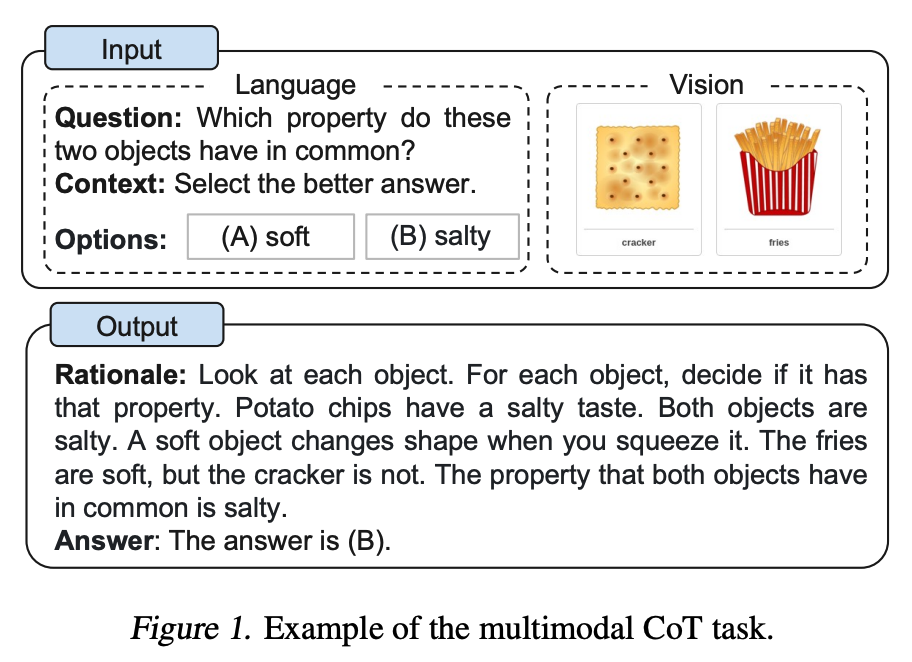
Fonte da imagem: Zhang et al. (2023) (opens in a new tab)
Leitura adicional: