LLaMA: Modelli linguistici di base aperti ed efficienti
Questa sezione è in fase di forte sviluppo.
Cosa c'è di nuovo?
Questo documento introduce una raccolta di modelli linguistici di base che vanno dai parametri 7B a 65B.
I modelli vengono addestrati su trilioni di token con set di dati disponibili pubblicamente.
Il lavoro di (Hoffman et al. 2022) (opens in a new tab) mostra che, dato un budget di calcolo, modelli più piccoli addestrati su molti più dati possono ottenere prestazioni migliori rispetto alle controparti più grandi. Questo lavoro raccomanda di addestrare modelli 10B su token 200B. Tuttavia, il documento LLaMA rileva che le prestazioni di un modello 7B continuano a migliorare anche dopo i token 1T.
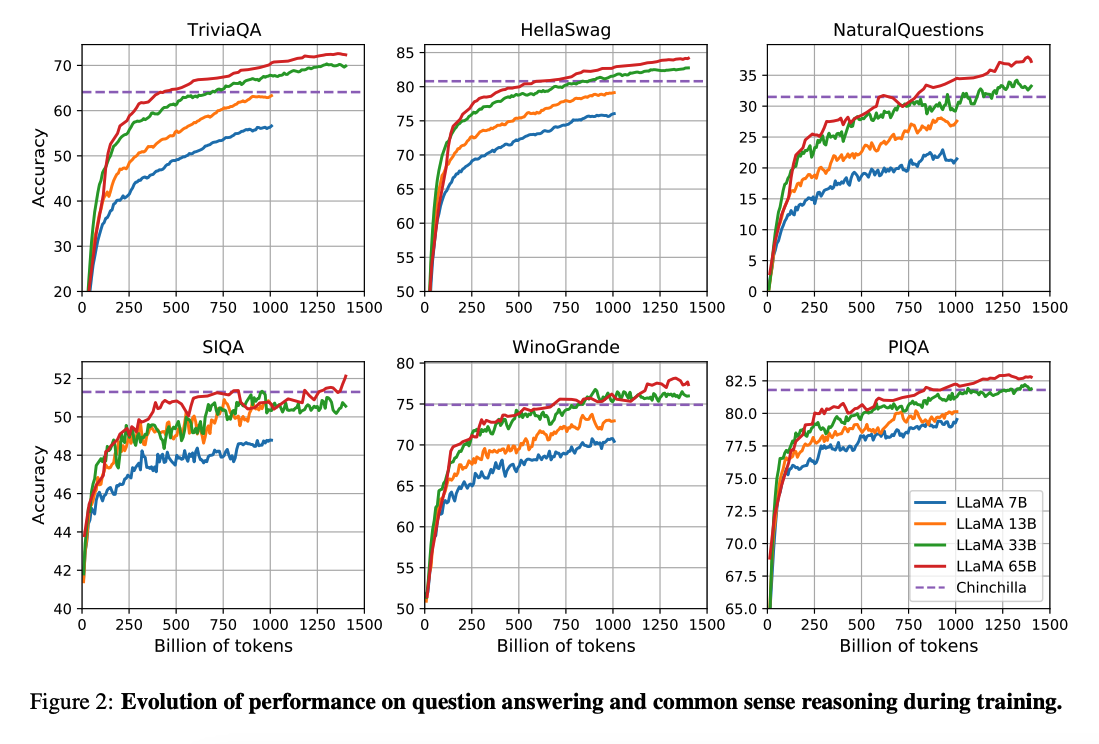
Questo lavoro si concentra sui modelli di addestramento (LLaMA) che raggiungono le migliori prestazioni possibili a vari budget di inferenza, addestrando su più token.
Capacità e risultati chiave
Nel complesso, LLaMA-13B supera GPT-3 (175B) su molti benchmark nonostante sia 10 volte più piccolo e possa eseguire una singola GPU. LLaMA 65B è competitivo con modelli come Chinchilla-70B e PaLM-540B.
Articolo scientifico: LLaMA: Open and Efficient Foundation Language Models (opens in a new tab)
Codice: https://github.com/facebookresearch/llama (opens in a new tab)
Referenze
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (Aprile 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (Aprile 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (Marzo 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (Marzo 2023)
- GPT4All (opens in a new tab) (Marzo 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (Marzo 2023)
- Stanford Alpaca (opens in a new tab) (Marzo 2023)