Multimodal CoT Prompt
Zhang et al. (2023) (opens in a new tab) ha recentemente proposto un approccio multimodale di suggerimento a catena di pensiero. Il CoT tradizionale si concentra sulla modalità linguistica. Al contrario, Multimodal CoT incorpora testo e visione in un quadro a due fasi. Il primo passo prevede la generazione di motivazioni basate su informazioni multimodali. Questa è seguita dalla seconda fase, l'inferenza della risposta, che sfrutta le motivazioni informative generate.
Il modello CoT multimodale (1B) supera GPT-3.5 sul benchmark ScienceQA.
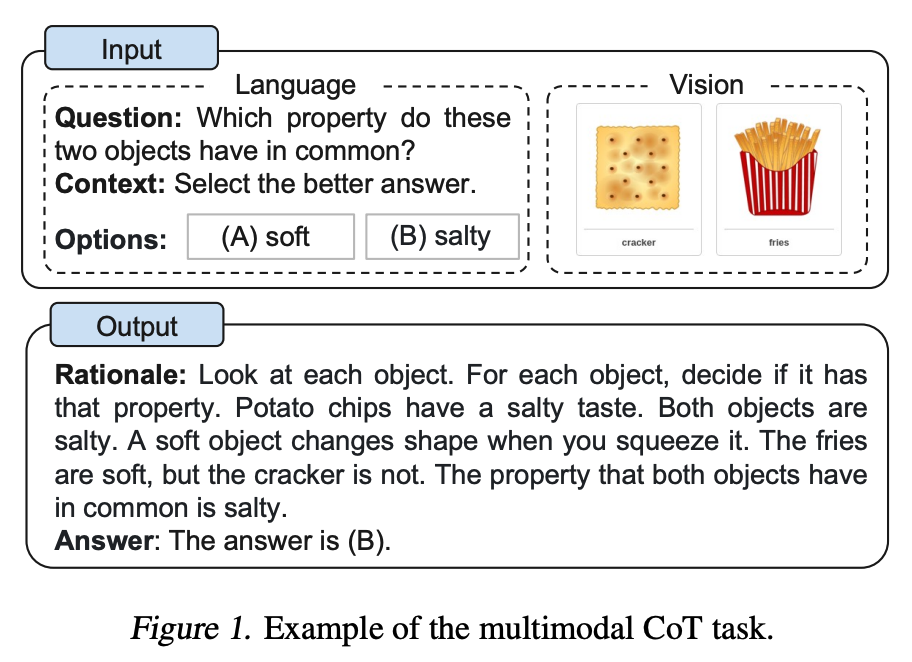
Sorgente Immagine: Zhang et al. (2023) (opens in a new tab)
Ulteriori letture: