Tree of Thoughts (ToT)
Per i compiti complessi che richiedono un'esplorazione o una visione strategica in avanti, le tecniche di prompting tradizionali o semplici non sono all'altezza. Yao et el. (2023) (opens in a new tab) e Long (2023) (opens in a new tab) hanno recentemente proposto Tree of Thoughts (ToT, albero dei pensieri), un framework che generalizza la richiesta di catene di pensieri e incoraggia l'esplorazione di pensieri che servono come passi intermedi per la risoluzione di problemi generali con modelli linguistici.
La tecnica ToT crea un albero di pensieri, dove i pensieri sono sequenze linguistiche coerenti che servono come passi intermedi per raggiungere la risoluzione del problema. Questo approccio permette ad un LM di valutare i suoi stessi progressi intermedi verso la risoluzione del problema. L'abilità dell'LM di generare e valutare i pensieri viene combinata con algoritmi di ricerca (es.: breadth-first search e depth-first search), in modo da esplorare sistematicamente i pensieri con lookahead e backtracking.
La tecnica ToT è illustrata nella seguente immagine:
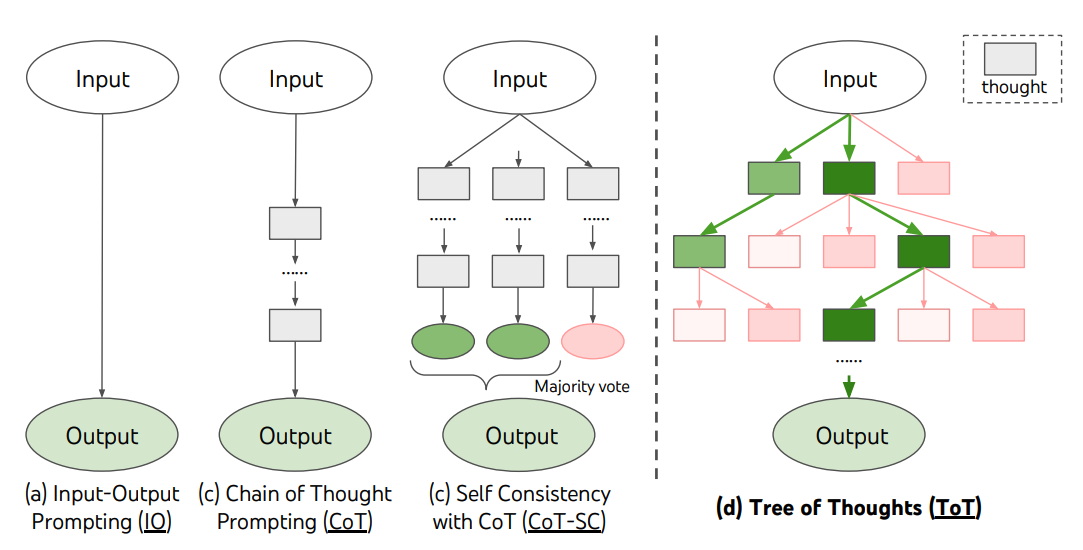
Fonte: Yao et el. (2023) (opens in a new tab)
Quando si usa la tecnica ToT, è necessario definire il numero di pensieri candidati (i più promettenti) ed il numero di passi necessari che l'LM deve effettuare per raggiungere la soluzione. Nel paper, il Gioco del 24 (opens in a new tab) viene utilizzato come task di ragionamento matematico che richiede una decomposizione in 3 passi, ognuno avente una equazione intermedia. Ad ogni passo, i migliori b=5 candidati vengono salvati.
Per effettuare una BFS (breadth-first search) nella tecnica ToT per il Gioco del 24, ogni passo candidato viene valutato in base alla possibilità di raggiungere il numero 24 attraverso l'operazione matematica proposta. Ad ognuno viene assegnata un'etichetta tra "sicuro/forse/impossibile". Come affermato dagli autori, lo scopo è quello di promuovere le soluzioni parziali corrette, che possono essere verificate guardando in avanti di pochi passi, eliminare le soluzioni parziali impossibili basandosi, per esempio, sulla grandezza del numero "il numero è troppo piccolo/grande per raggiungere 24 nei prossimi step", e tenere il resto, quelle etichettate con "forse". I valori vengono campionati 3 volte per ogni passo. Il processo è illustrato nell'immagine:
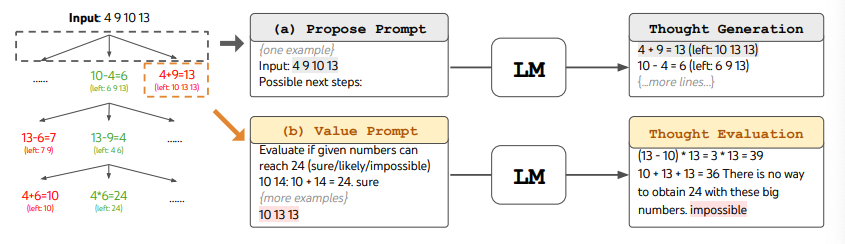
Fonte: Yao et el. (2023) (opens in a new tab)
Dai risultati riportati nella figura sotto, la tecnica ToT risulta migliore delle altre tecniche di prompting:
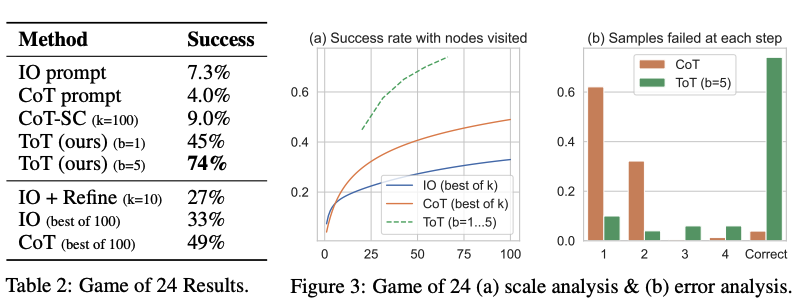
Fonte: Yao et el. (2023) (opens in a new tab)
Codice disponibile qui (opens in a new tab) e qui (opens in a new tab)
Ad alto livello, le principali idee di Yao et el. (2023) (opens in a new tab) e Long (2023) (opens in a new tab) sono simili. Entrambe potenziano le capacità dei Large Language Model di risolvere problemi complessi utilizzando una ricerca ad albero tramite una conversazione a più turni. Una delle differenze principali sta nelle strategie di ricerca utilizzate: Yao et el. (2023) (opens in a new tab) utilizza algoritmi generici di ricerca come DFS/BFS/beam search, mentre la strategia di ricerca (cioè quando effettuare backtracking e di quanti livelli nell'albero, ecc.) proposta da Long (2023) (opens in a new tab) è controllata da un "ToT Controller", addestrato utilizzando il reinforcement learning (RL, apprendimento per rinforzo). DFS/BFS/Beam search sono algoritmi di ricerca generici, senza alcun adattamento a problemi specifici. Un ToT Controller, invece, essendo addestrato tramite RL potrebbe essere in grado di imparare da dati nuovi o attraverso il gioco contro se stesso (AlphaGo vs ricerca a forza bruta), e quindi il sistema di ToT basato su RL può continuare a evolversi e ad apprendere nuove conoscenze anche con un LLM fisso.
Hulbert (2023) (opens in a new tab) ha proposto la tecnica di Tree-of-Thought Prompting, che applica il concetto principale della tecnica ToT facendo in modo che l'LLM valuti i pensieri intermedi utilizzando un singolo prompt testuale. Un esempio di prompt ToT è il seguente:
Immagina che tre differenti esperti rispondano a questa domanda.
Tutti gli esperti scrivono un passo del loro ragionamento,
poi lo condividono con il gruppo.
In seguito, tutti gli esperti andranno al passo successivo, etc.
Se uno degli esperti capisce di aver sbagliato dopo essere arrivato ad un qualsiasi passo, l'esperto abbandona il gruppo.
La domanda è...Sun (2023) (opens in a new tab) ha effettuato un benchmark del prompt Tree-of-Thought con esperimenti su larga scala e ha introdotto PanelGPT --- un'idea di prompting con discussioni di gruppo tra gli LLM.