Scaling Instruction-Finetuned Language Models
¿Qué hay de nuevo?
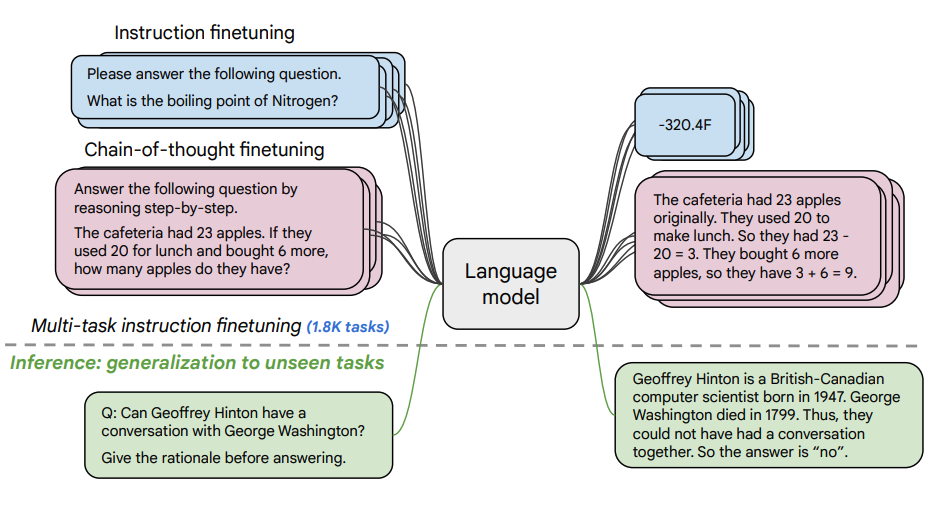
Fuente de la imagen: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Este documento explora los beneficios del escalado del ajuste de instrucciones (instruction finetuning (opens in a new tab)) y cómo mejora el rendimiento en una variedad de modelos (PaLM, T5), configuraciones de prompts (zero-shot, few-shot, CoT) y referencias (MMLU, TyDiQA). Esto se explora con los siguientes aspectos: escalar el número de tareas (1,8K tareas), escalar el tamaño del modelo y ajustar los datos en la cadena de pensamiento (se usaron 9 conjuntos de datos).
Procedimiento de finetuning:
- 1.8K tareas se formularon como instrucciones y se usaron para ajustar el modelo
- Se utilizan tanto con como sin ejemplos, y con y sin CoT
Se muestran las tareas de finetuning y las tareas retenidas a continuación:
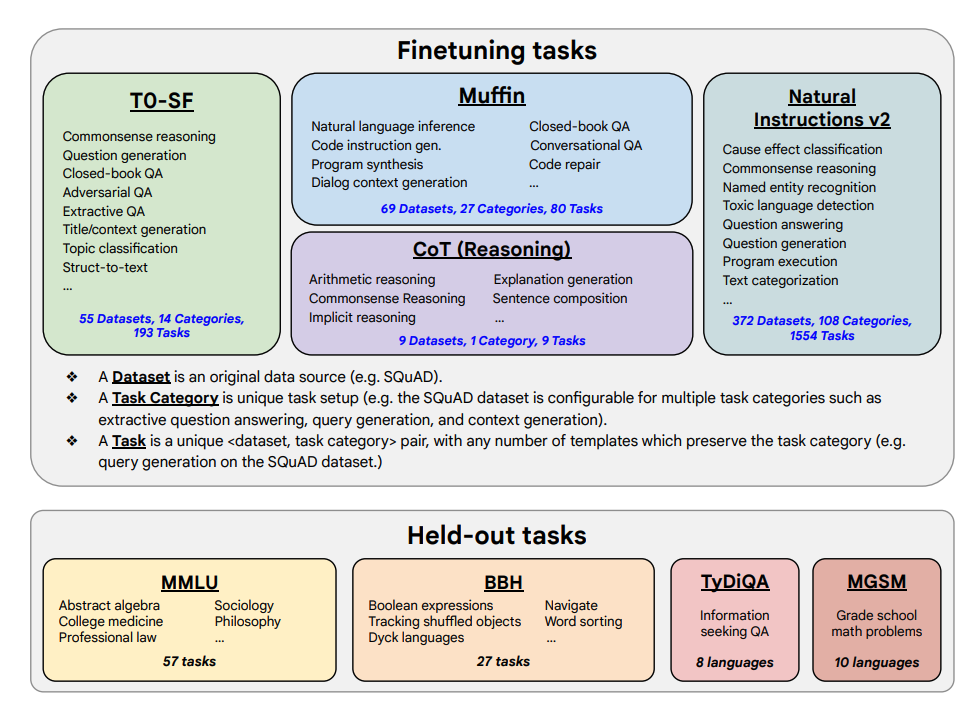
Capacidades y resultados clave
- El ajuste de instrucciones escala bien con el número de tareas y el tamaño del modelo; esto sugiere la necesidad de escalar el número de tareas y el tamaño del modelo aún más
- Agregar conjuntos de datos CoT en el finetuning permite un buen rendimiento en tareas de razonamiento
- Flan-PaLM tiene mejores habilidades multilingües; mejora del 14.9% en TyDiQA de una sola pasada; mejora del 8.1% en razonamiento aritmético en idiomas subrepresentados
- Plan-PaLM también tiene un buen rendimiento en preguntas de generación abierta, lo que es un buen indicador de una mejor usabilidad
- Mejora el rendimiento en referencias de IA responsable (RAI)
- Los modelos de ajuste de instrucciones de Flan-T5 demuestran fuertes capacidades de few-shot y superan a los puntos de control públicos como T5
Los resultados al escalar el número de tareas de ajuste y el tamaño del modelo: se espera que la escalabilidad tanto del tamaño del modelo como del número de tareas de ajuste continúe mejorando el rendimiento, aunque la escalabilidad del número de tareas tiene retornos disminuidos.
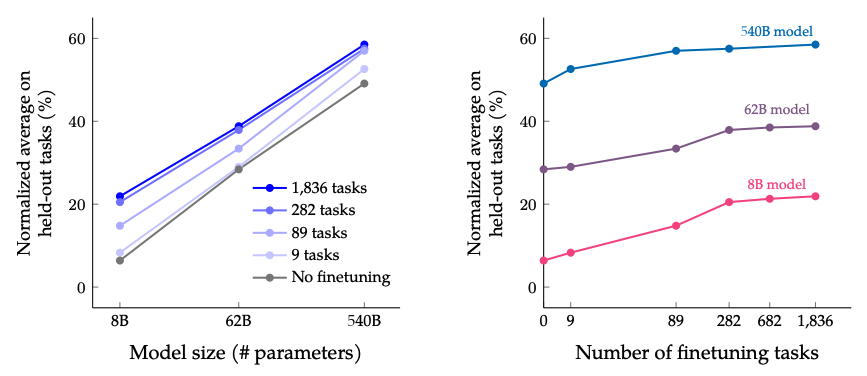
Fuente de la imagen: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Resultados al ajustar con datos no-CoT y CoT: El ajuste conjunto con datos no-CoT y CoT mejora el rendimiento en ambas evaluaciones, en comparación con el ajuste en solo uno u otro.
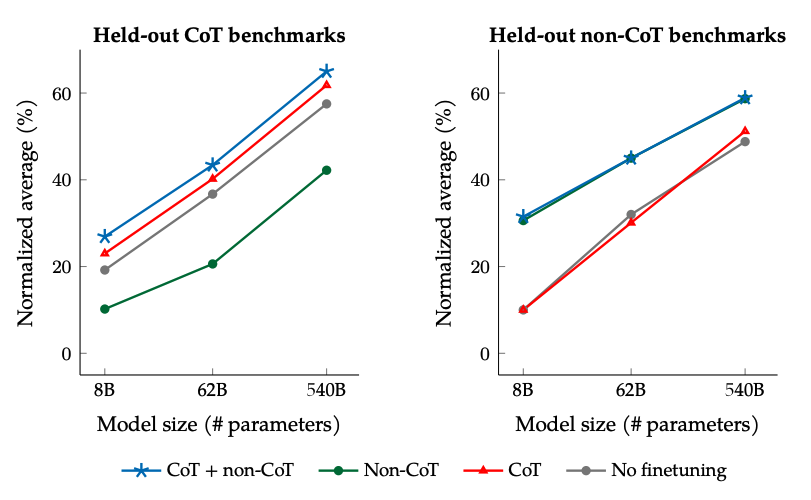
Fuente de la imagen: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Además, la autoconsistencia combinada con CoT logra resultados de estado del arte en varios benchmarks. CoT + autoconsistencia también mejora significativamente los resultados en benchmarks que involucran problemas matemáticos (por ejemplo, MGSM, GSM8K).
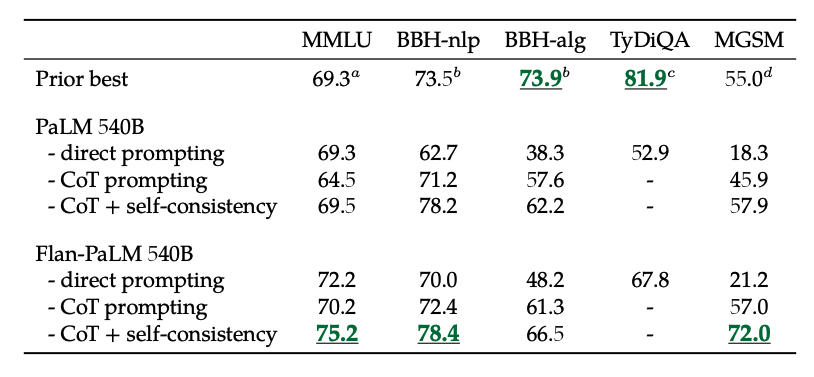
Fuente de la imagen: Scaling Instruction-Finetuned Language Models (opens in a new tab)
El ajuste de CoT desbloquea el razonamiento sin ayuda (zero-shot), activado por la frase "pensemos paso a paso", en tareas de BIG-Bench. En general, Flan-PaLM CoT sin ayuda supera en rendimiento a PaLM CoT sin ajuste.
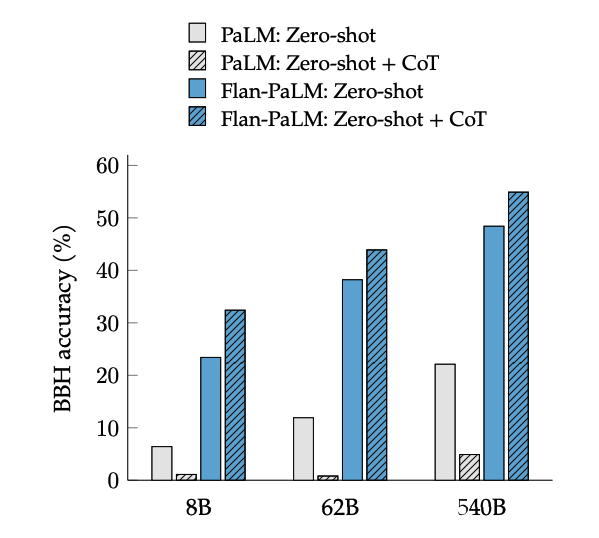
Fuente de la imagen: Scaling Instruction-Finetuned Language Models (opens in a new tab)
A continuación se presentan algunas demostraciones de CoT sin ayuda para PaLM y Flan-PaLM en tareas no vistas.
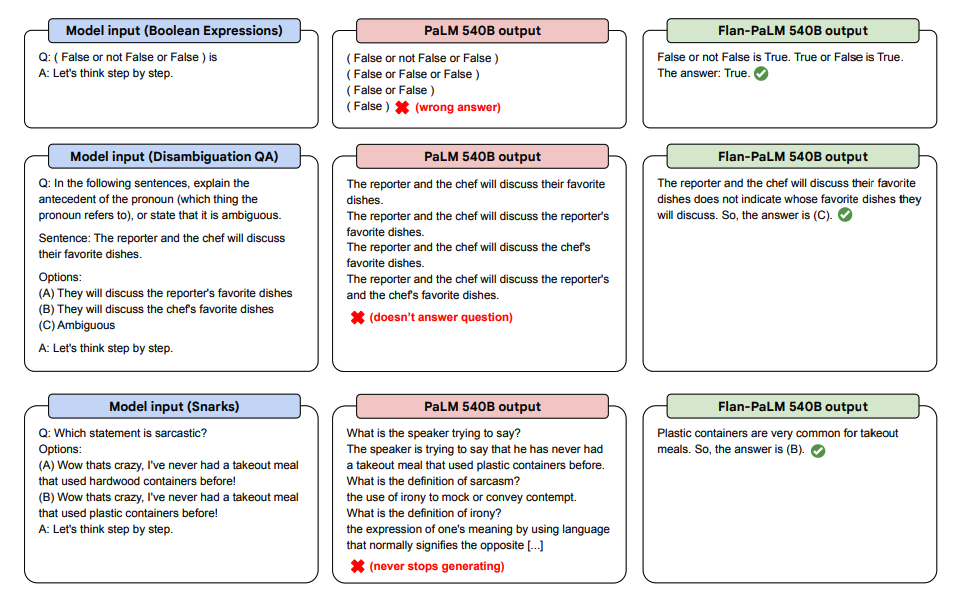
Fuente de la imagen: Scaling Instruction-Finetuned Language Models (opens in a new tab)
A continuación se presentan más ejemplos de prompts zero-shot. Muestra cómo el modelo PaLM tiene dificultades con las repeticiones y no responde a las instrucciones en el ajuste sin ayuda, mientras que Flan-PaLM puede desempeñarse bien. Los ejemplos con pocos ejemplos pueden mitigar estos errores.
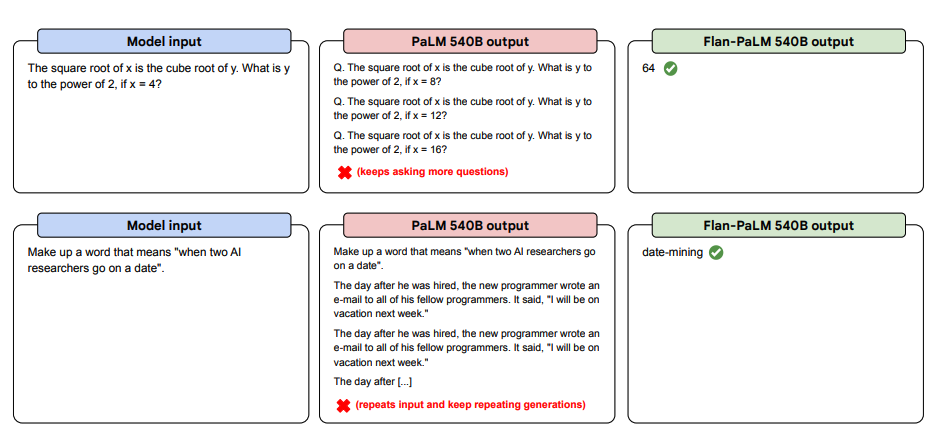
Fuente de la imagen: Scaling Instruction-Finetuned Language Models (opens in a new tab)
A continuación se presentan algunos ejemplos que demuestran las capacidades sin ayuda (zero-shot) del modelo Flan-PaLM en varios tipos diferentes de preguntas abiertas complejas:
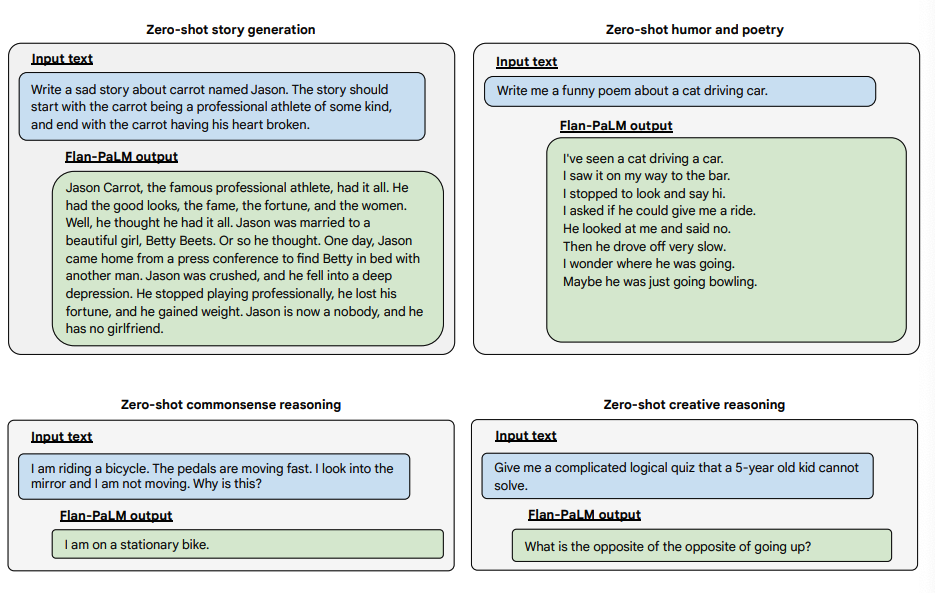
Fuente de la imagen: Scaling Instruction-Finetuned Language Models (opens in a new tab)
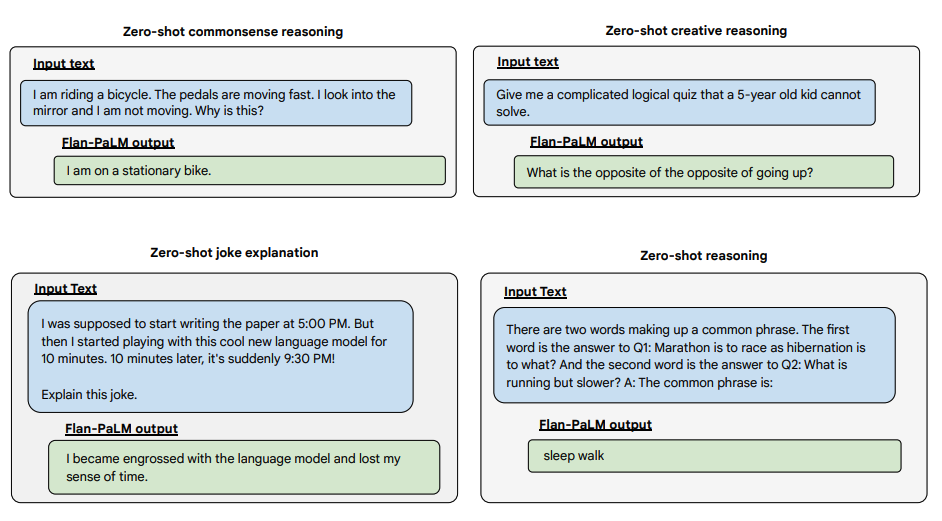
Fuente de la imagen: Scaling Instruction-Finetuned Language Models (opens in a new tab)
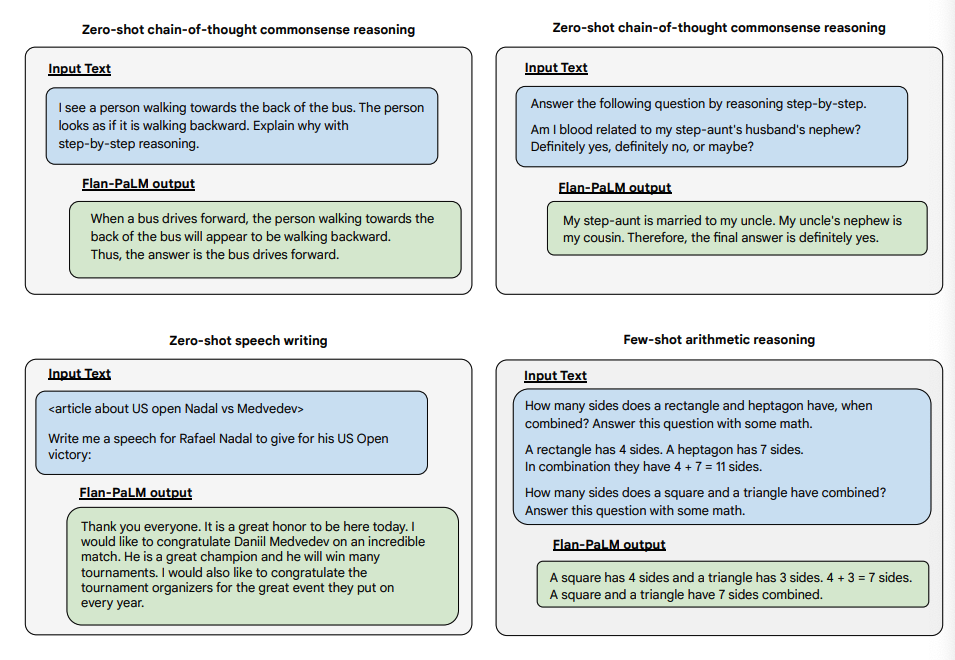
Fuente de la imagen: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Puedes probar los modelos Flan-T5 en el Hugging Face Hub (opens in a new tab).