Prompt CoT multimodal
Zhang et al. (2023) (opens in a new tab) propusieron recientemente un enfoque de generación de cadenas de pensamiento multimodales. El CoT tradicional se centra en la modalidad del lenguaje. En cambio, el CoT multimodal incorpora texto y visión en un marco de dos etapas. El primer paso implica la generación de razones basadas en información multimodal. Esto es seguido por la segunda fase, la inferencia de respuestas, que aprovecha las razones generadas informativas.
El modelo CoT multimodal (1B) supera al GPT-3.5 en el banco de pruebas de ScienceQA.
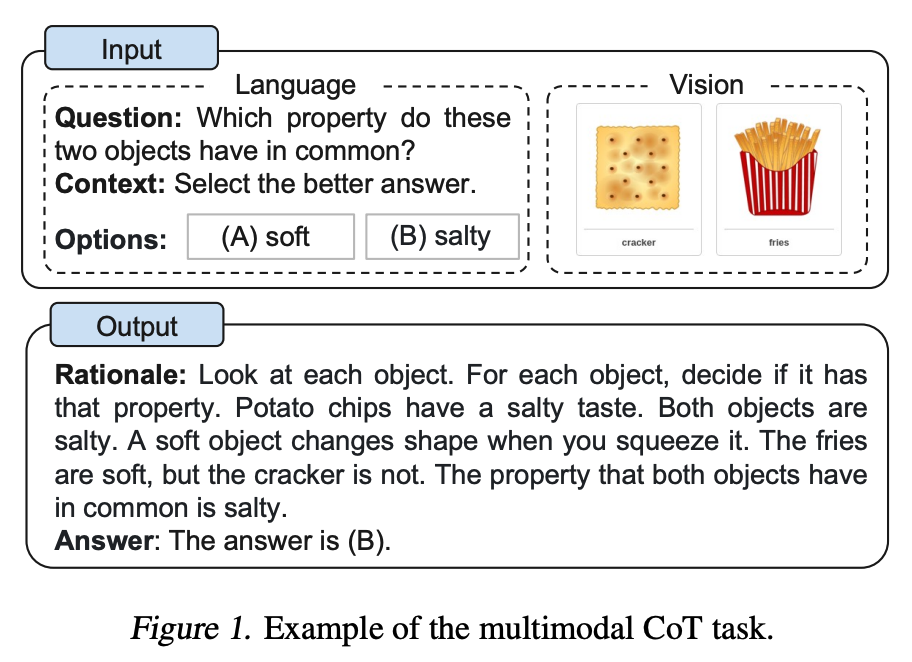
Fuente de imagen: Zhang et al. (2023) (opens in a new tab)
Lectura adicional: