LLaMA: Open and Efficient Foundation Language Models
Esta sección está en pleno desarrollo.
¿Qué hay de nuevo?
Este paper presenta una colección de modelos de lenguaje fundamentales que van desde 7B hasta 65B de parámetros.
Los modelos están entrenados con trillones de tokens con conjuntos de datos disponibles públicamente.
El trabajo de (Hoffman et al. 2022) (opens in a new tab) muestra que, dado un presupuesto de computación, los modelos más pequeños entrenados con mucha más datos pueden lograr un mejor rendimiento que los modelos más grandes. Este trabajo recomienda entrenar modelos de 10B con 200B tokens. Sin embargo, el artículo de LLaMA encuentra que el rendimiento de un modelo de 7B sigue mejorando incluso después de 1T de tokens.
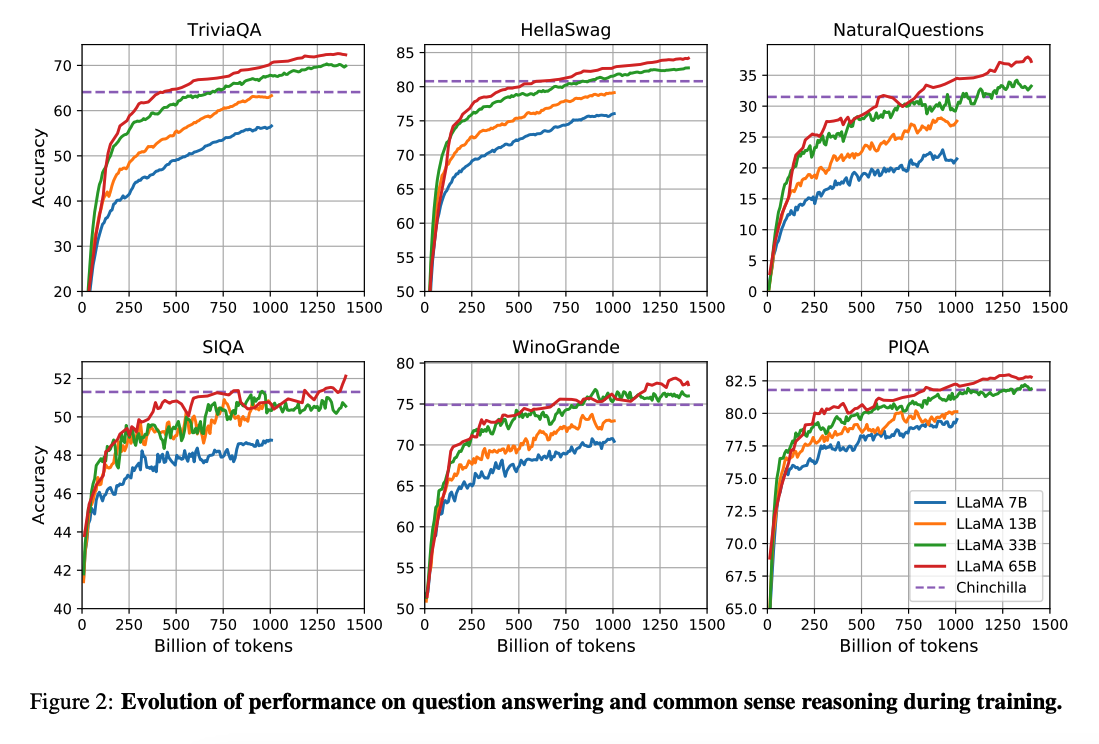
Este trabajo se centra en entrenar modelos (LLaMA) que logren el mejor rendimiento posible en varios presupuestos de inferencia, mediante el entrenamiento de más tokens.
Capacidades y resultados clave
En general, LLaMA-13B supera a GPT-3(175B) en muchos puntos de referencia a pesar de ser 10 veces más pequeño y posible de ejecutar en una sola GPU. LLaMA 65B es competitivo con modelos como Chinchilla-70B y PaLM-540B.
Paper: LLaMA: Open and Efficient Foundation Language Models (opens in a new tab)
Code: https://github.com/facebookresearch/llama (opens in a new tab)
Referencias
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (March 2023)
- GPT4All (opens in a new tab) (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (March 2023)
- Stanford Alpaca (opens in a new tab) (March 2023)