LLaMA : modèles de langage de base ouverts et efficaces
Cette section est en plein développement.
Quoi de neuf?
Cet article présente une collection de modèles de langage de base allant des paramètres 7B à 65B.
Les modèles sont formés sur un billion de jetons avec des ensembles de données accessibles au public.
Les travaux de (Hoffman et al. 2022) (opens in a new tab) montrent qu'avec un budget de calcul, des modèles plus petits entraînés sur beaucoup plus de données peuvent obtenir de meilleures performances que leurs homologues plus grands. Ce travail recommande de former des modèles 10B sur des jetons 200B. Cependant, le document LLaMA constate que les performances d'un modèle 7B continuent de s'améliorer même après les jetons 1T.
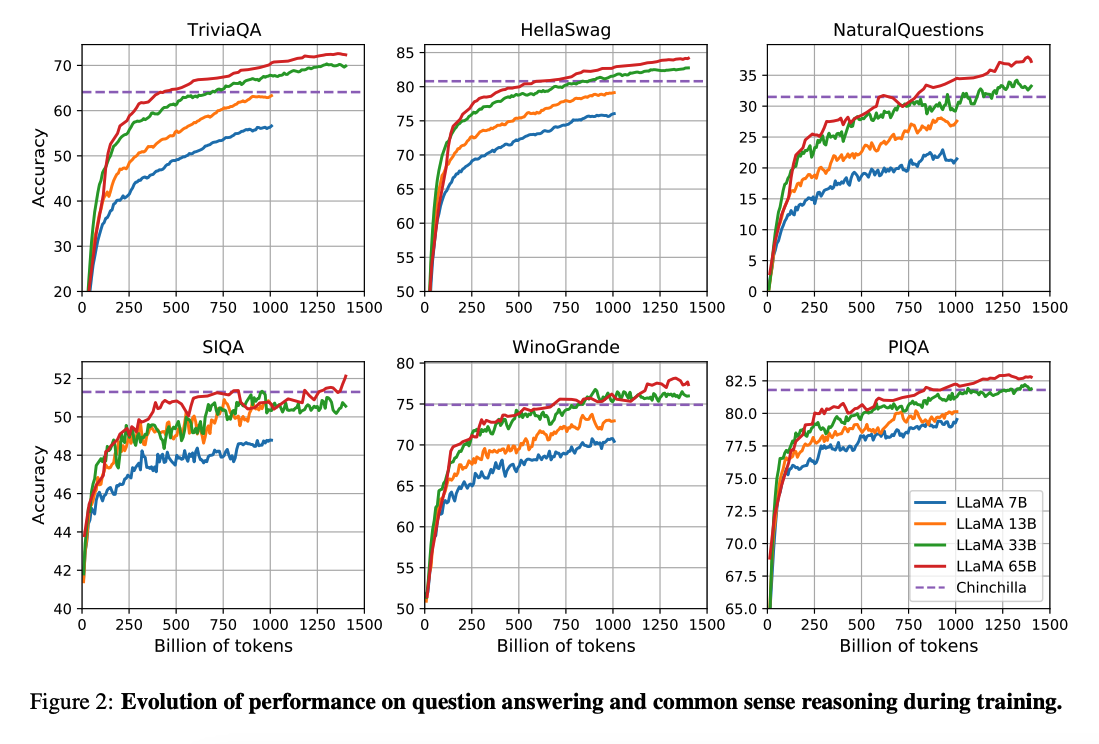
Ce travail se concentre sur les modèles d'entraînement (LLaMA) qui atteignent les meilleures performances possibles à différents budgets d'inférence, en s'entraînant sur plus de jetons.
Capacités et résultats clés
Dans l'ensemble, LLaMA-13B surpasse GPT-3 (175B) sur de nombreux benchmarks malgré le fait qu'il soit 10 fois plus petit et qu'il soit possible d'exécuter un seul GPU. LLaMA 65B est compétitif avec des modèles comme Chinchilla-70B et PaLM-540B.
Article : [LLaMA : modèles de langage de base ouverts et efficaces] (https://arxiv.org/abs/2302.13971 (opens in a new tab))
Code: https://github.com/facebookresearch/llama (opens in a new tab)
Les références
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (March 2023)
- GPT4All (opens in a new tab) (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (March 2023)
- Stanford Alpaca (opens in a new tab) (March 2023)