Génération Augmentée par Récupération (RAG)
En anglais : "Retrieval Augmented Generation", communément abrégé en RAG
Les modèles de langage polyvalents peuvent être affinés pour réaliser plusieurs tâches courantes telles que l'analyse de sentiments et la reconnaissance d'entités nommées. Ces tâches ne nécessitent généralement pas de connaissances supplémentaires.
Pour des tâches plus complexes et exigeantes en connaissances, il est possible de construire un système basé sur un modèle de langage qui accède à des sources de connaissances externes pour compléter les tâches. Cela permet une plus grande cohérence factuelle, améliore la fiabilité des réponses générées et aide à atténuer le problème des "hallucinations".
Les chercheurs de Meta AI ont introduit une méthode appelée Génération Augmentée par Récupération (RAG) pour aborder de telles tâches exigeantes en connaissances. RAG combine un composant de récupération d'informations avec un modèle générateur de texte. RAG peut être affiné et ses connaissances internes peuvent être modifiées de manière efficace et sans nécessiter une reformation complète du modèle.
RAG prend une entrée et récupère un ensemble de documents pertinents/supportants donnés par une source (par exemple, Wikipédia). Les documents sont concaténés comme contexte avec la demande d'entrée originele et fournis au générateur de texte qui produit la sortie finale. Cela rend le RAG adaptable pour des situations où les faits pourraient évoluer avec le temps. Cela est très utile car la connaissance paramétrique des LLM est statique. le RAG permet aux modèles de langage de contourner la reformation, permettant l'accès aux informations les plus récentes pour générer des sorties fiables via la génération basée sur la récupération.
Lewis et al., (2021) ont proposé une recette de raffinement polyvalente pour le RAG. Un modèle seq2seq pré-entraîné est utilisé comme mémoire paramétrique et un index vectoriel dense de Wikipédia est utilisé comme mémoire non paramétrique (accédée à l'aide d'un récupérateur pré-entraîné par réseau de neurones). Voici un aperçu de la façon dont l'approche fonctionne :
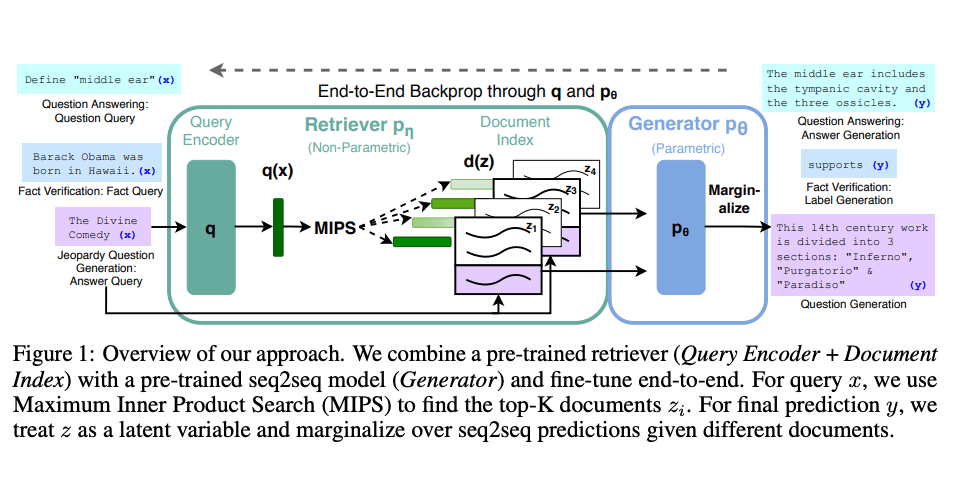
Source de l'image : Lewis et el. (2021) (opens in a new tab) Un RAG est performant sur plusieurs benchmarks tels que Natural Questions, WebQuestions, et CuratedTrec. Le RAG génère des réponses plus factuelles, spécifiques et diversifiées lorsqu'il est testé sur des questions MS-MARCO et Jeopardy. le RAG améliore également les résultats sur la vérification des faits FEVER.
Cela montre le potentiel de RAG comme une option viable et pertinente pour améliorer les sorties des modèles de langage dans des tâches exigeantes en connaissances.
Plus récemment, ces approches basées sur la récupération sont devenues plus populaires et sont combinées avec des LLM bien connus comme ChatGPT pour améliorer les capacités et la cohérence factuelle.
Cas d'utilisation d'un RAG : Générer des titres d'articles de machine learning facilement.
Ci-dessous, nous avons préparé un tutoriel afin de montrer l'utilisation de LLM open-source pour construire un système RAG pour générer des titres courts et concis d'articles sur l'apprentissage automatique :
Vous voulez en savoir plus sur le RAG ? Découvrez notre nouveau cours basé sur des cohortes (opens in a new tab). Utilisez le code promo MAVENAI20 pour une réduction de 20%.
Références
(en français en dessous)
-
Retrieval-Augmented Generation for Large Language Models: A Survey (opens in a new tab) (Dec 2023) FR : Génération Augmentée par Récupération pour les Grands Modèles de Langage : Une synthèse (document EN) (opens in a new tab) (Déc 2023)
-
Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models (opens in a new tab) (Sep 2020) FR : Génération Augmentée par Récupération : Rationaliser la création de modèles de traitement naturel du langage intelligents (doc EN) (opens in a new tab) (Sep 2020)