Multimodal CoT Prompting
Zhang et al. (2023) (opens in a new tab) ont récemment proposé une approche multimodale d'incitation à la chaîne de pensée. Le CoT traditionnel se concentre sur la modalité linguistique. En revanche, le CoT multimodal intègre le texte et la vision dans un cadre en deux étapes. La première étape consiste à générer une justification basée sur des informations multimodales. Ceci est suivi par la deuxième phase, l'inférence de réponse, qui exploite les justifications informatives générées.
Le modèle multimodal CoT (1B) surpasse GPT-3.5 sur le benchmark ScienceQA.
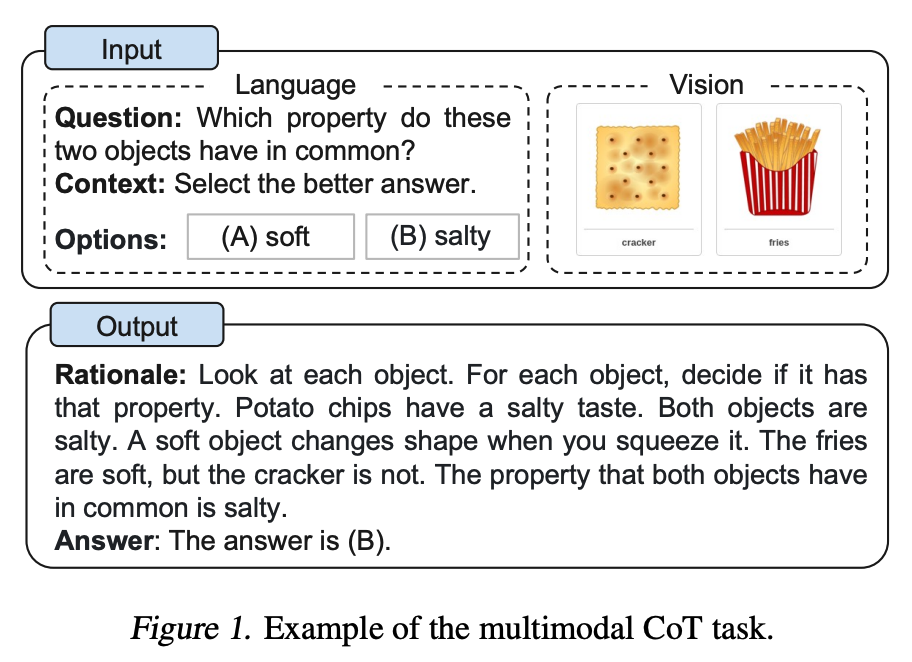
Image Source: Zhang et al. (2023) (opens in a new tab)
Lecture complémentaire :
- [La langue n'est pas tout ce dont vous avez besoin : aligner la perception sur les modèles linguistiques] (https://arxiv.org/abs/2302.14045 (opens in a new tab)) (février 2023)