Tree of Thoughts (ToT)
Pour des tâches complexes qui nécessitent une exploration ou une anticipation stratégique, les techniques de prompt traditionnelles ou simples sont insuffisantes. Yao et al. (2023) (opens in a new tab) et Long (2023) (opens in a new tab) ont récemment proposé "Tree of Thoughts" (ToT), un framework qui généralise le prompt "chain-of-thought" et encourage l'exploration à travers des pensées qui servent d'étapes intermédiaires pour la résolution de problèmes généraux avec des modèles de langage.
ToT maintient un arbre de pensées, où les pensées représentent des séquences de langage cohérentes qui servent d'étapes intermédiaires vers la résolution d'un problème. Cette approche permet à un LLM d'auto-évaluer les progrès à travers les pensées intermédiaires réalisées vers la résolution d'un problème grâce à un processus de raisonnement délibéré. La capacité du LLM à générer et évaluer les pensées est ensuite combinée avec des algorithmes de recherche (par exemple, recherche en largeur et recherche en profondeur) pour permettre une exploration systématique des pensées avec anticipation et retour en arrière.
Le framework ToT est illustré ci-dessous :
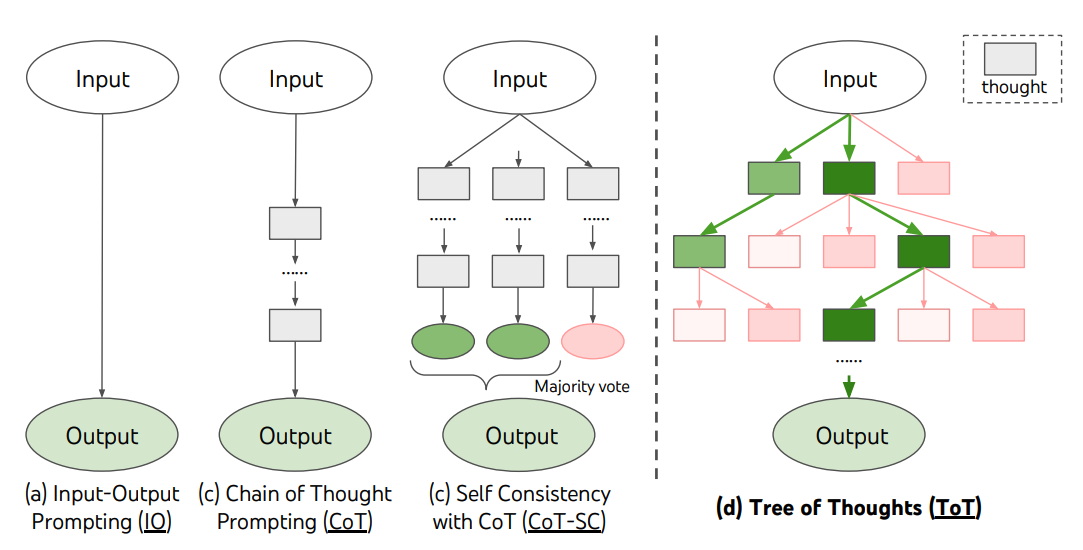
Source de l'image : Yao et al. (2023) (opens in a new tab)
Lors de l'utilisation de ToT, différentes tâches nécessitent de définir le nombre de candidats et le nombre de pensées/étapes. Par exemple, comme démontré dans l'article, le Jeu des 24 est utilisé comme une tâche de raisonnement mathématique qui nécessite de décomposer les pensées en 3 étapes, chacune impliquant une équation intermédiaire. À chaque étape, les 5 meilleurs candidats sont conservés.
Pour effectuer une recherche en largeur dans ToT pour la tâche du Jeu des 24, le LLM est invité à évaluer chaque candidat de pensée comme "sûr/peut-être/impossible" par rapport à l'objectif d'atteindre 24. Comme l'indiquent les auteurs, "l'objectif est de promouvoir des solutions partielles correctes qui peuvent être jugées dans quelques essais, d'éliminer les solutions partielles impossibles en se basant sur le bon sens 'trop grand/petit', et de garder les 'peut-être'". Les valeurs sont échantillonnées 3 fois pour chaque pensée. Le processus est illustré ci-dessous :
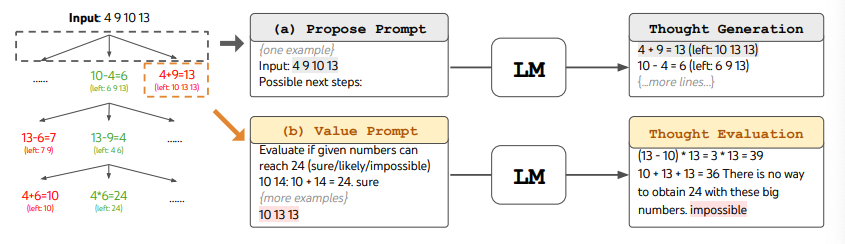
Source de l'image : Yao et al. (2023) (opens in a new tab)
D'après les résultats rapportés dans la figure ci-dessous, ToT surpasse considérablement les autres méthodes de prompt :
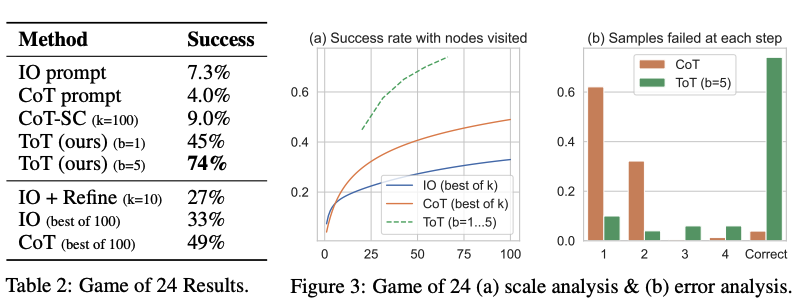
Source de l'image : Yao et al. (2023) (opens in a new tab)
Code disponible ici (opens in a new tab) et ici (opens in a new tab)
À un niveau plus élevé, les idées principales de Yao et al. (2023) (opens in a new tab) et Long (2023) (opens in a new tab) sont similaires. Les deux améliorent la capacité des LLM à résoudre des problèmes complexes par la recherche d'arbres via une conversation en plusieurs tours. Une des principales différences est que Yao et al. (2023) (opens in a new tab) utilise la recherche via parcours en largeur/profondeur/par faisceaux, tandis que la stratégie de recherche d'arbres (c'est-à-dire quand revenir en arrière et revenir en arrière de combien de niveaux, etc.) proposée dans Long (2023) (opens in a new tab) est pilotée par un "Contrôleur ToT" formé par apprentissage par renforcement (RL). La recherche via parcours en largeur/profondeur/par faisceaux sont des stratégies génériques de recherche de solutions sans adaptation à des problèmes spécifiques. En comparaison, un Contrôleur ToT formé par RL pourrait apprendre à partir d'un nouvel ensemble de données ou par auto-apprentissage (AlphaGo vs recherche par force brute), et donc le système ToT basé sur RL peut continuer à évoluer et apprendre de nouvelles connaissances même avec un LLM fixe.
Hulbert (2023) (opens in a new tab) a proposé le "Tree-of-Thought Prompting", qui applique le concept principal des frameworks ToT comme une technique de prompt simple, amenant le LLM à évaluer les pensées intermédiaires dans un seul prompt. Un exemple de prompt ToT est :
Imaginez que trois experts différents répondent à cette question.
Tous les experts écriront 1 étape de leur réflexion,
puis la partageront avec le groupe.
Ensuite, tous les experts passeront à l'étape suivante, etc.
Si un expert se rend compte qu'il a tort à un moment donné, alors il part.
La question est...Sun (2023) (opens in a new tab) a évalué le "Tree-of-Thought Prompting" avec des expériences à grande échelle, et introduit PanelGPT --- une idée du prompting avec des tables rondes entre LLM.