Generierung eines synthetischen Datensatzes für RAG
Synthetische Daten für RAG-Setup
Leider gibt es im Leben eines Machine Learning Ingenieurs oft einen Mangel an gelabelten Daten oder sehr wenige davon. Typischerweise beginnen Projekte, nachdem sie dies bemerkt haben, mit einem langwierigen Prozess der Datensammlung und -kennzeichnung. Erst nach einigen Monaten kann man mit der Entwicklung einer Lösung beginnen.
Mit dem Aufkommen der LLMs hat sich das Paradigma bei einigen Produkten jedoch verschoben: Nun kann man sich auf die Generalisierungsfähigkeit von LLMs verlassen und fast sofort eine Idee testen oder ein KI-gesteuertes Feature entwickeln. Wenn sich herausstellt, dass es (beinahe) wie beabsichtigt funktioniert, kann der traditionelle Entwicklungsprozess beginnen.

Bildquelle: The Rise of the AI Engineer, von S. Wang (opens in a new tab)
Einer der aufkommenden Ansätze ist Retrieval Augmented Generation (RAG) (opens in a new tab). Es wird für wissensintensive Aufgaben verwendet, bei denen man sich nicht allein auf das Wissen des Modells verlassen kann. RAG kombiniert eine Informationswiederfindungskomponente mit einem Textgenerierungsmodell. Um mehr über diesen Ansatz zu erfahren, lesen Sie bitte den entsprechenden Abschnitt im Leitfaden (opens in a new tab).
Die Schlüsselkomponente von RAG ist ein Retrieval-Modell, das relevante Dokumente identifiziert und an LLMs zur weiteren Verarbeitung weiterleitet. Je besser die Leistung des Retrieval-Modells ist, desto besser ist das Ergebnis des Produkts oder Features. Idealweise funktioniert Retrieval sofort gut. Allerdings sinkt dessen Leistung oft in verschiedenen Sprachen oder spezifischen Domänen.
Stellen Sie sich vor: Sie müssen einen Chatbot erstellen, der Fragen basierend auf tschechischen Gesetzen und rechtlichen Praktiken beantwortet (natürlich auf Tschechisch). Oder Sie entwerfen einen Steuerassistenten (ein Anwendungsfall, der von OpenAI während der Präsentation von GPT-4 vorgestellt wurde), der für den indischen Markt maßgeschneidert ist. Sie werden wahrscheinlich feststellen, dass das Retrieval-Modell oft nicht die relevantesten Dokumente findet und insgesamt nicht so gut funktioniert, was die Qualität des Systems einschränkt.
Aber es gibt eine Lösung. Ein aufkommender Trend besteht darin, bestehende LLMs zu nutzen, um Daten für das Training neuer Generationen von LLMs/Retrievers/anderen Modellen zu synthetisieren. Dieser Prozess kann als Destillieren von LLMs in standardgroße Encoder über prompt-basierte Abfragegenerierung betrachtet werden. Obwohl die Destillation rechenintensiv ist, reduziert sie die Inferenzkosten erheblich und könnte die Leistung, besonders in spracharmen oder spezialisierten Domänen, erheblich steigern.
In diesem Leitfaden verlassen wir uns auf die neuesten Textgenerierungsmodelle, wie ChatGPT und GPT-4, welche große Mengen an synthetischen Inhalten nach Anweisungen produzieren können. Dai et al. (2022) (opens in a new tab) schlugen eine Methode vor, bei der mit nur 8 manuell gelabelten Beispielen und einem großen Korpus an ungelabelten Daten (Dokumente für das Retrieval, z. B. alle verarbeiteten Gesetze) eine nahezu State-of-the-Art-Leistung erzielt werden kann. Diese Forschung bestätigt, dass synthetisch generierte Daten das Training von aufgabenspezifischen Retrieval-Modellen für Aufgaben erleichtern, bei denen supervised in-domain Fine-Tuning eine Herausforderung aufgrund von Datenknappheit ist.
Domänenspezifische Datensatzgenerierung
Um LLMs zu nutzen, muss man eine kurze Beschreibung liefern und einige Beispiele manuell kennzeichnen. Es ist wichtig zu beachten, dass verschiedene Retrieval-Aufgaben unterschiedliche Suchintentionen besitzen, was bedeutet, dass sich die Definition von "Relevanz" unterscheidet. Anders ausgedrückt, für dasselbe Paar (Abfrage, Dokument) könnte ihre Relevanz völlig unterschiedlich sein, basierend auf der Suchintention. Beispielsweise sucht eine Argumentfindungsaufgabe nach unterstützenden Argumenten, während andere Aufgaben Gegenargumente erfordern (wie im ArguAna-Datensatz (opens in a new tab) zu sehen).
Betrachten Sie das folgende Beispiel. Obwohl es zur leichteren Verständnis auf Englisch geschrieben ist, erinnern Sie sich daran, dass Daten in jeder Sprache sein können, da ChatGPT/GPT-4 auch weniger verbreitete Sprachen effizient verarbeiten kann.
Prompt:
Task: Identify a counter-argument for the given argument.
Argument #1: {insert passage X1 here}
A concise counter-argument query related to the argument #1: {insert manually prepared query Y1 here}
Argument #2: {insert passage X2 here}
A concise counter-argument query related to the argument #2: {insert manually prepared query Y2 here}
<- paste your examples here ->
Argument N: Even if a fine is made proportional to income, you will not get the equality of impact you desire. This is because the impact is not proportional simply to income, but must take into account a number of other factors. For example, someone supporting a family will face a greater impact than someone who is not, because they have a smaller disposable income. Further, a fine based on income ignores overall wealth (i.e. how much money someone actually has: someone might have a lot of assets but not have
a high income). The proposition does not cater for these inequalities, which may well have a much greater skewing effect, and therefore the argument is being applied inconsistently.
A concise counter-argument query related to the argument #N:Output:
punishment house would make fines relative incomeGenerell kann ein solcher Prompt wie folgt ausgedrückt werden:
, wobei und jeweils aufgabenspezifische Dokument- und Abfragebeschreibungen sind, ist eine aufgabenspezifische Prompt/Anweisung für ChatGPT/GPT-4, und ist ein neues Dokument, für welches LLM eine Abfrage generieren wird.
Von diesem Prompt werden nur das letzte Dokument und die generierte Abfrage für das weitere Training des lokalen Modells verwendet. Dieser Ansatz kann angewendet werden, wenn ein zielspezifischer Retrieval-Korpus verfügbar ist, aber die Anzahl der annotierten Abfrage-Dokument-Paare für die neue Aufgabe begrenzt ist.
Der Gesamtüberblick über die Pipeline:
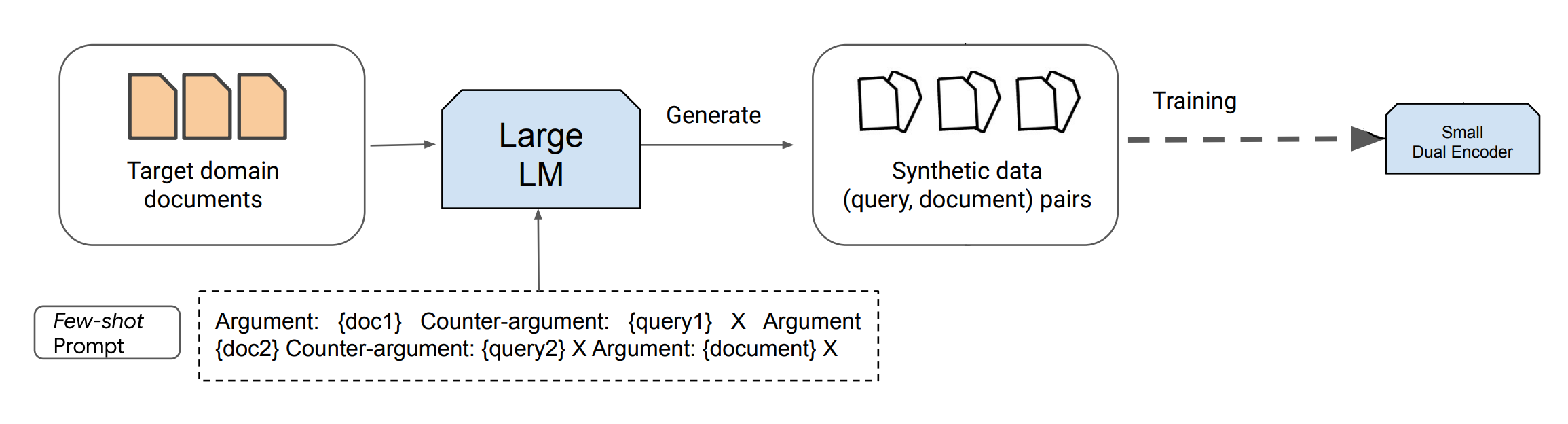
Bildquelle: Dai et al. (2022) (opens in a new tab)
Es ist entscheidend, die manuelle Annotation von Beispielen verantwortungsbewusst zu handhaben. Es ist besser, mehr vorzubereiten (beispielsweise 20) und zufällig 2-8 davon zum Prompt hinzuzufügen. Dies erhöht die Vielfalt der generierten Daten ohne signifikante Zeitkosten beim Annotieren. Diese Beispiele sollten allerdings repräsentativ sein, korrekt formatiert und sogar Details wie die angestrebte Abfragelänge oder deren Ton spezifizieren. Je präziser die Beispiele und Anweisungen sind, desto besser wird die synthetische Datenqualität für das Training des Retrievers sein. Beispiele von schlechter Qualität können sich negativ auf die resultierende Qualität des trainierten Modells auswirken.
In den meisten Fällen ist die Verwendung eines kostengünstigeren Modells wie ChatGPT ausreichend, da es gut mit ungewöhnlichen Domänen und Sprachen, die nicht Englisch sind, zurechtkommt. Angenommen, ein Prompt mit Anweisungen und 4-5 Beispielen benötigt typischerweise 700 Token (wobei davon ausgegangen wird, dass jeder Abschnitt aufgrund von Retrieval-Einschränkungen nicht länger als 128 Token ist) und die Generierung ist 25 Token. Somit würden die Kosten für die Erstellung eines synthetischen Datensatzes für ein Korpus von 50.000 Dokumenten für das lokale Modell-Fine-Tuning betragen: 50.000 * (700 * 0.001 * $0.0015 + 25 * 0.001 * $0.002) = 55, wobei $0.0015 und $0.002 die Kosten pro 1.000 Token in der GPT-3.5 Turbo-API sind. Es ist sogar möglich, 2-4 Abfragebeispiele für dasselbe Dokument zu generieren. Dennoch sind die Vorteile des weiteren Trainings oft lohnenswert, besonders wenn Sie Retriever nicht für eine allgemeine Domäne (wie Nachrichtensuche auf Englisch) sondern für eine spezifische verwenden (wie tschechische Gesetze, wie erwähnt).
Die Zahl von 50.000 ist nicht willkürlich. In der Forschung von Dai et al. (2022) (opens in a new tab) wird angegeben, dass dies ungefähr die Anzahl an manuell gelabelten Daten ist, die ein Modell benötigt, um die Qualität eines auf synthetischen Daten trainierten Modells zu erreichen. Stellen Sie sich vor, Sie müssten mindestens 10.000 Beispiele sammeln, bevor Sie Ihr Produkt auf den Markt bringen! Das würde nicht weniger als einen Monat dauern und die Arbeitskosten würden sicherlich tausend Dollar übersteigen, viel mehr als das Erzeugen von synthetischen Daten und das Training eines lokalen Retriever-Modells. Jetzt können Sie mit der Technik, die Sie heute gelernt haben, innerhalb weniger Tage ein zweistelliges Wachstum der Metriken erreichen!
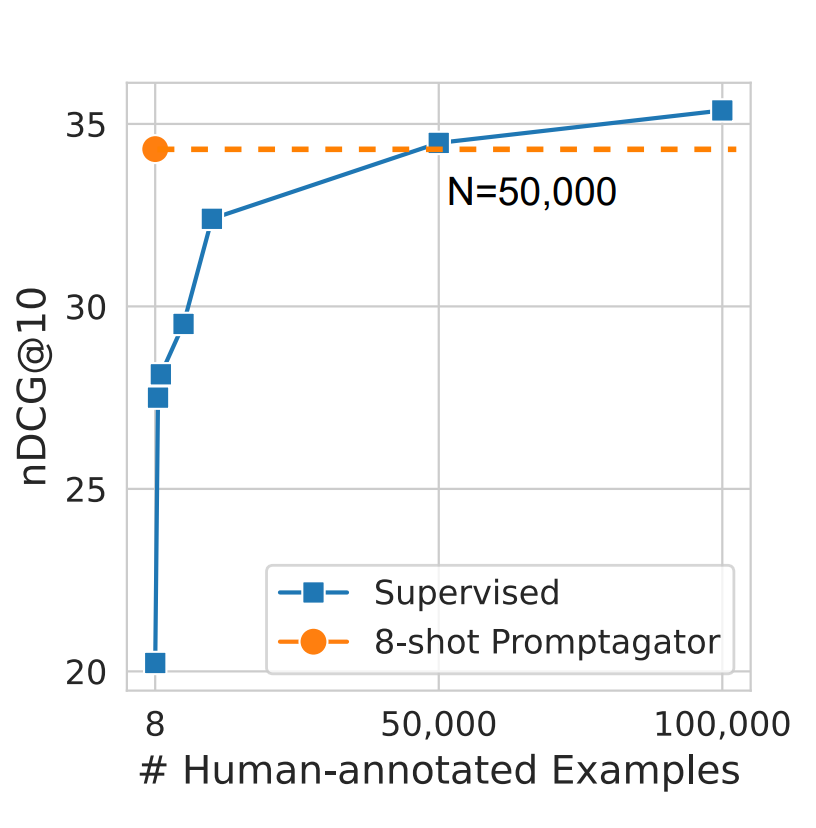
Bildquelle: Dai et al. (2022) (opens in a new tab)
Und hier sind Prompt-Vorlagen aus demselben Papier für einige der Datensätze im BeIR-Benchmark.

Bildquelle: Dai et al. (2022) (opens in a new tab)