Automatic Reasoning and Tool-use (ART)
Die Kombination von CoT-Prompting und Werkzeugeinsatz in einer verzahnten Art und Weise hat sich als starker und robuster Ansatz erwiesen, um viele Aufgaben mit LLMs zu behandeln. Diese Ansätze erfordern in der Regel handgefertigte, aufgabenspezifische Demonstrationen und sorgfältig skriptgesteuertes Verzahnen von Modellgenerierungen mit Werkzeugnutzung. Paranjape et al., (2023) (opens in a new tab) schlagen einen neuen Rahmen vor, der ein eingefrorenes LLM nutzt, um automatisch Zwischenschritte im Schlussfolgern als ein Programm zu generieren.
ART funktioniert wie folgt:
- zuerst werden für eine neue Aufgabe Demonstrationen von mehrschrittigem Schlussfolgern und Werkzeugnutzung aus einer Aufgabenbibliothek ausgewählt
- zur Laufzeit setzt es die Generierung aus, sobald externe Werkzeuge aufgerufen werden, und integriert deren Ausgabe, bevor die Generierung wieder aufgenommen wird
ART ermutigt das Modell, von Demonstrationen zu generalisieren, um eine neue Aufgabe zu zerlegen und Werkzeuge an geeigneten Stellen einzusetzen, und zwar auf zero-shot Weise. Darüber hinaus ist ART erweiterbar, da es auch Menschen ermöglicht, Fehler in den Schlussfolgerungsschritten zu korrigieren oder neue Werkzeuge hinzuzufügen, indem einfach die Aufgaben- und Werkzeugbibliotheken aktualisiert werden. Der Prozess wird unten demonstriert:
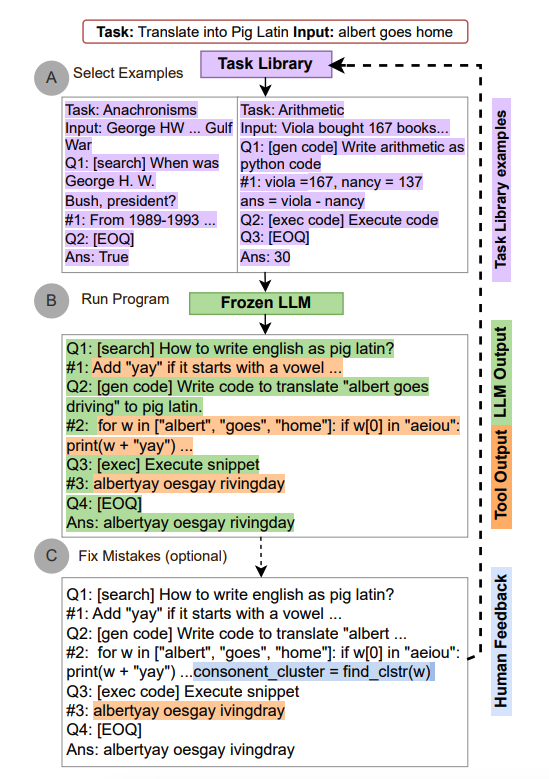
Bildquelle: Paranjape et al., (2023) (opens in a new tab)
ART verbessert sich deutlich gegenüber Few-shot-Prompting und automatischem CoT bei unbekannten Aufgaben in den BigBench- und MMLU-Benchmarks und übertrifft die Leistung von handgefertigten CoT-Prompts, wenn Menschenrückmeldungen eingebunden werden.
Unten finden Sie eine Tabelle, die die Leistung von ART bei BigBench- und MMLU-Aufgaben zeigt:
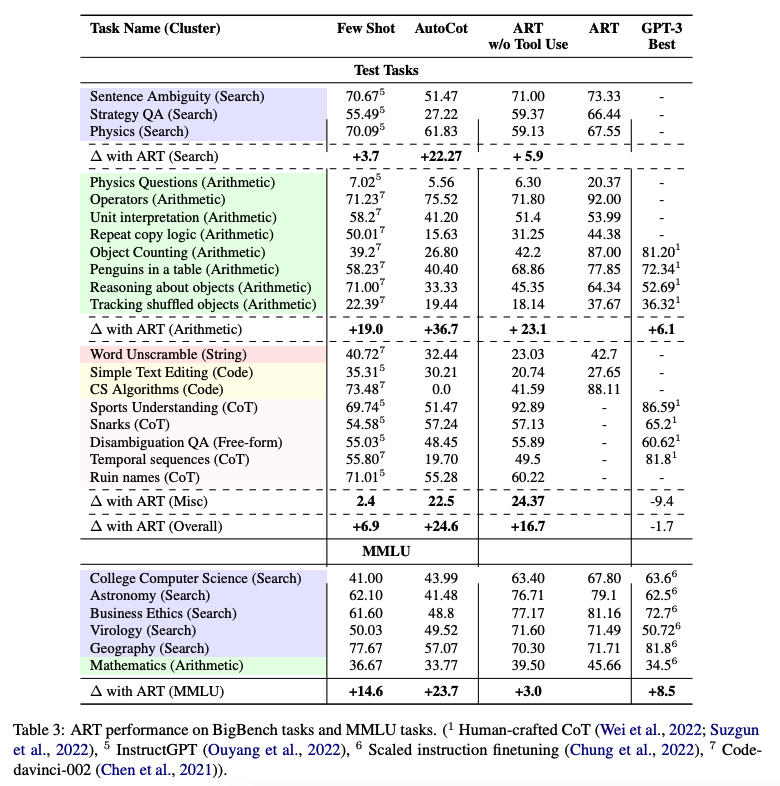
Bildquelle: Paranjape et al., (2023) (opens in a new tab)