LLM In-Context Recall hängt vom Prompt ab
Dieses neue Paper von Machlab und Battle (2024) (opens in a new tab) analysiert die In-Context Recall-Leistung verschiedener LLMs anhand mehrerer Nadel-im-Heuhaufen-Tests.
Es zeigt, dass verschiedene LLMs Fakten auf unterschiedlichen Längen und in verschiedener Tiefe erinnern. Es stellt fest, dass die Recall-Leistung eines Modells erheblich durch kleine Änderungen im Prompt beeinflusst wird.
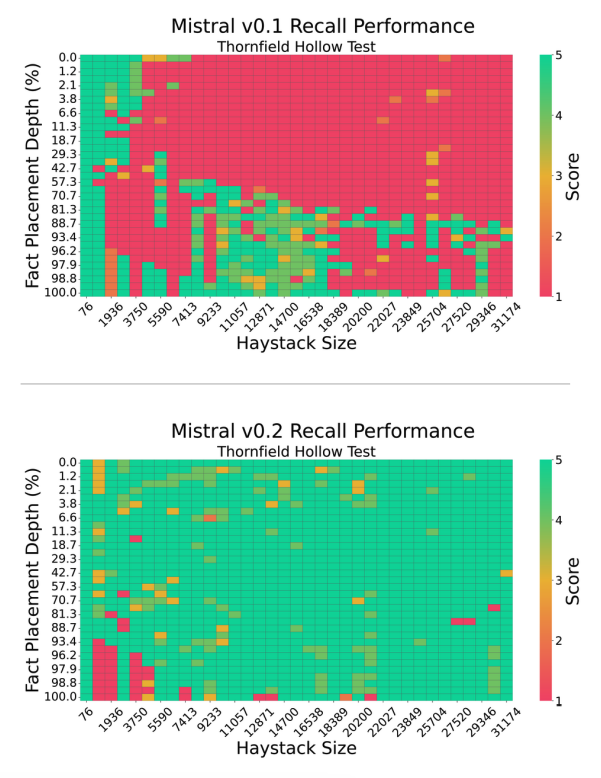 Quelle: Machlab und Battle (2024) (opens in a new tab)
Quelle: Machlab und Battle (2024) (opens in a new tab)
Darüber hinaus kann das Zusammenspiel zwischen Prompt-Inhalt und Trainingsdaten die Antwortqualität verschlechtern.
Die Recall-Fähigkeit eines Modells kann durch Vergrößerung, Verbesserung des Attention-Mechanismus, das Ausprobieren verschiedener Trainingsstrategien und das Anwenden von Fine-Tuning verbessert werden.
Wichtiger praktischer Tipp aus dem Paper: „Die fortlaufende Bewertung wird die Auswahl von LLMs für individuelle Anwendungsfälle weiter informieren, ihre Wirkung und Effizienz in realen Anwendungen maximieren, da die Technologie weiterhin fortschreitet.“
Die wichtigsten Erkenntnisse aus diesem Paper sind die Bedeutung einer sorgfältigen Gestaltung des Prompts, die Einrichtung eines kontinuierlichen Bewertungsprotokolls und das Testen verschiedener Modellverbesserungsstrategien, um Recall und Nutzen zu verbessern.