Multimodales CoT Prompting
Zhang et al. (2023) (opens in a new tab) schlugen kürzlich einen multimodalen Ansatz für Chain-of-Thought (CoT) Prompting vor. Traditionelles CoT konzentriert sich auf die Sprachmodalität. Im Gegensatz dazu bezieht Multimodales CoT Text und Vision in einen zweistufigen Rahmen mit ein. Der erste Schritt beinhaltet die Generierung von Begründungen basierend auf multimodalen Informationen. Darauf folgt die zweite Phase, die Inferenz der Antwort, welche die informativen generierten Begründungen nutzt.
Das multimodale CoT-Modell (1B) übertrifft GPT-3.5 im ScienceQA-Benchmark.
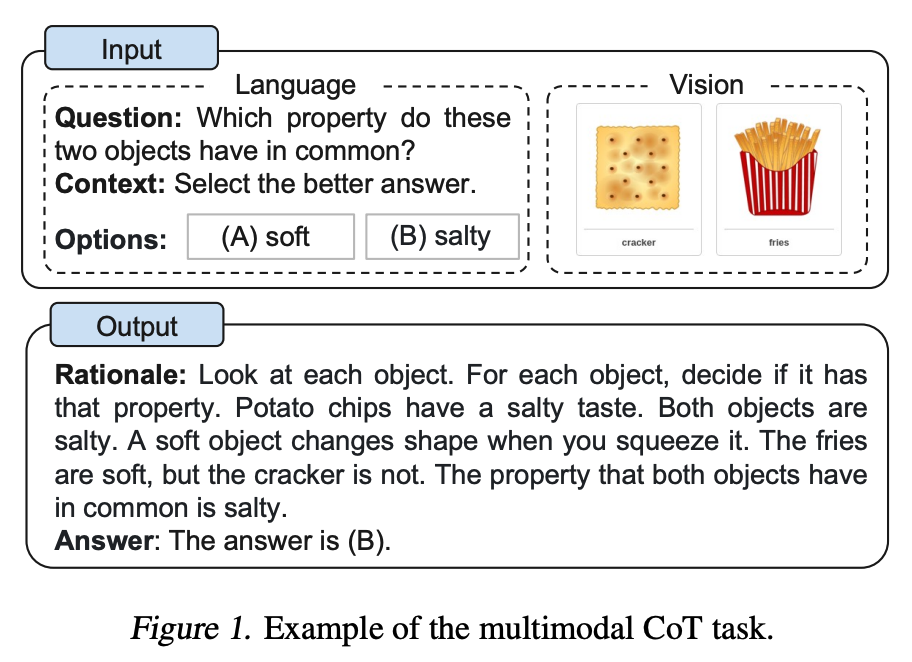
Bildquelle: Zhang et al. (2023) (opens in a new tab)
Weiterführende Literatur: