Wie zuverlässig sind RAG-Modelle?
Dieses neue Paper von Wu et al. (2024) (opens in a new tab) zielt darauf ab, das Kräftemessen zwischen den RAG-Modellen und der internen Priorisierung von LLMs zu quantifizieren.
Es konzentriert sich dabei auf GPT-4 und andere LLMs bei der Beantwortung von Fragen zur Analyse.
Es wurde festgestellt, dass das Bereitstellen korrekter abgerufener Informationen die meisten Fehler des Modells korrigiert (94% Genauigkeit).
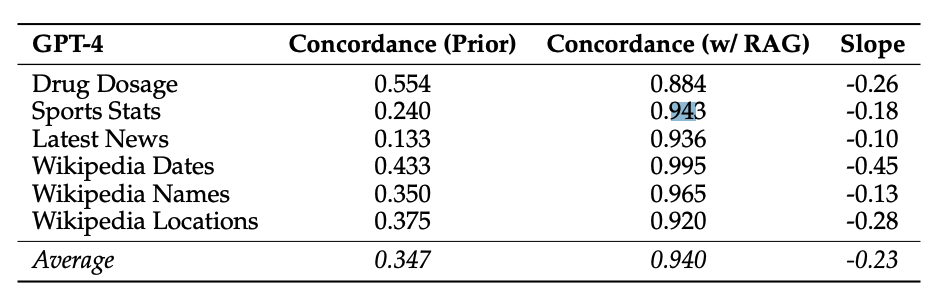 Quelle: Wu et al. (2024) (opens in a new tab)
Quelle: Wu et al. (2024) (opens in a new tab)
Wenn die Dokumente mehr falsche Werte enthalten und das interne Priorisieren des LLM schwach ist, neigt das LLM eher dazu, falsche Informationen wiederzugeben. Es wurde jedoch festgestellt, dass die LLMs widerstandsfähiger sind, wenn sie eine stärkere Vorprägung haben.
Das Paper berichtet auch, dass „je mehr die modifizierte Information von der Vorprägung des Modells abweicht, desto unwahrscheinlicher ist es, dass das Modell sie bevorzugt.“
Viele Entwickler und Unternehmen setzen RAG-Systeme in der Produktion ein. Diese Arbeit hebt die Bedeutung der Risikobewertung bei der Verwendung von LLMs hervor, die verschiedene Arten von Kontextinformationen enthalten können, die unterstützende, widersprüchliche oder völlig inkorrekte Informationen enthalten können.