Llama 3
Meta hat kürzlich ihre neue Familie großer Sprachmodelle (LLMs), genannt Llama 3, vorgestellt (opens in a new tab). Diese Veröffentlichung umfasst vorab trainierte und anweisungsoptimierte Modelle mit 8 Milliarden und 70 Milliarden Parametern.
Architekturdetails zu Llama 3
Hier eine Zusammenfassung der technischen Details von Llama 3:
- Es verwendet einen standardmäßigen Decoder-only-Transformer.
- Der Wortschatz umfasst 128K Token.
- Es wird auf Sequenzen von 8K Token trainiert.
- Es wendet gruppierte Abfrageaufmerksamkeit (GQA) an.
- Es ist auf über 15T Token vorab trainiert.
- Es beinhaltet eine Nachtrainierung, die eine Kombination aus SFT, Ablehnungs-Stichprobenentnahme, PPO und DPO einschließt.
Leistung
Auffällig ist, dass Llama 3 8B (anweisungsoptimiert) Gemma 7B (opens in a new tab) und Mistral 7B Instruct (opens in a new tab) übertrifft. Llama 3 70 übertrifft deutlich Gemini Pro 1.5 (opens in a new tab) und Claude 3 Sonnet (opens in a new tab), bleibt jedoch beim MATH-Benchmark etwas hinter Gemini Pro 1.5 zurück.
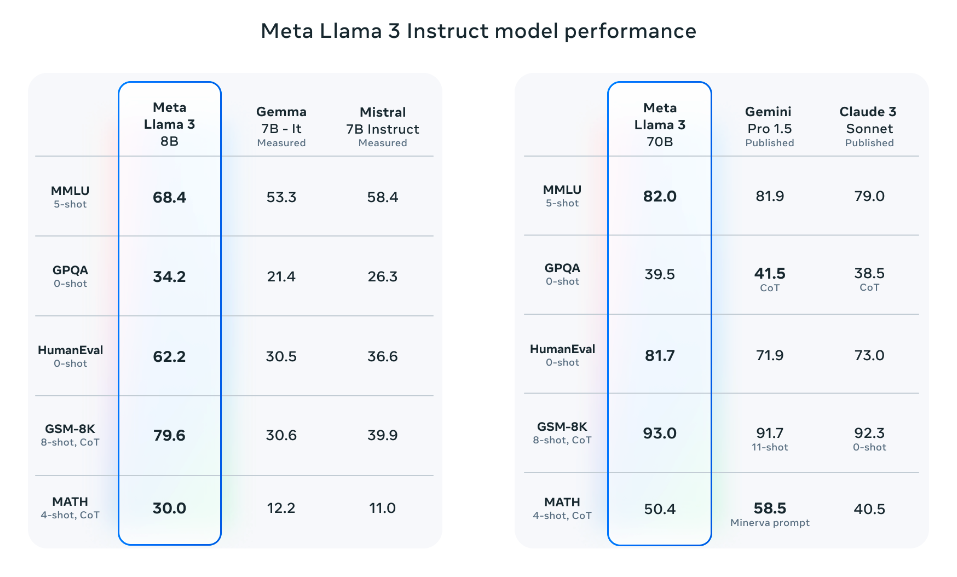 Quelle: Meta AI (opens in a new tab)
Quelle: Meta AI (opens in a new tab)
Die vorab trainierten Modelle übertreffen ebenfalls andere Modelle bei mehreren Benchmarks wie AGIEval (Englisch), MMLU und Big-Bench Hard.
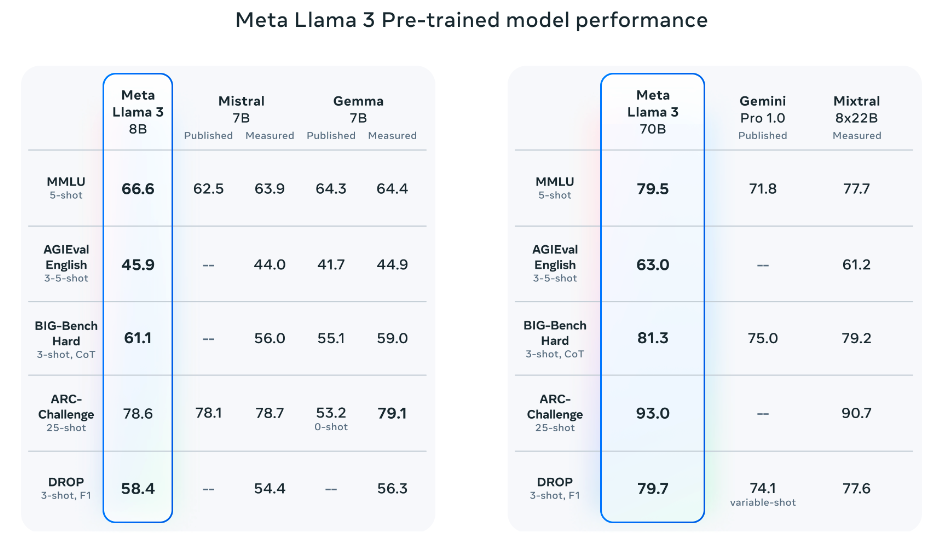 Quelle: Meta AI (opens in a new tab)
Quelle: Meta AI (opens in a new tab)
Llama 3 400B
Meta berichtete auch, dass sie ein Modell mit 400 Milliarden Parametern veröffentlichen werden, das derzeit noch trainiert wird und bald verfügbar sein soll! Es gibt auch Bemühungen um multimodale Unterstützung, mehrsprachige Fähigkeiten und längere Kontextfenster. Der aktuelle Checkpoint für Llama 3 400B (Stand 15. April 2024) liefert die folgenden Ergebnisse bei gängigen Benchmarks wie MMLU und Big-Bench Hard:
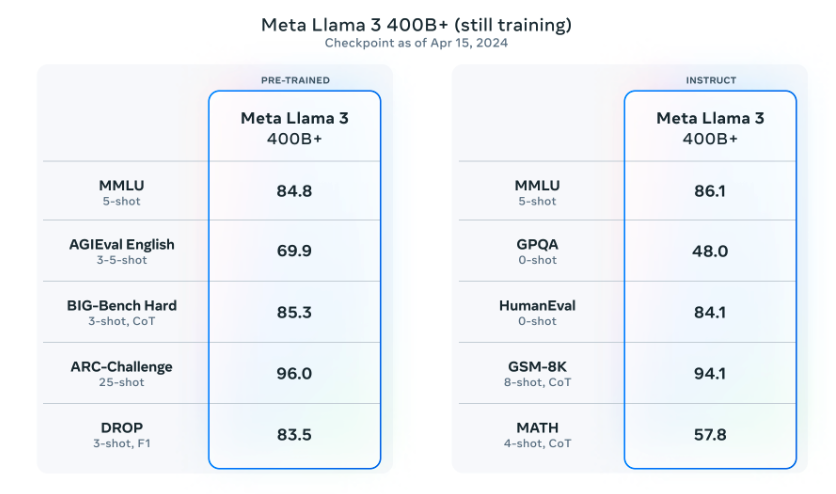 Quelle: Meta AI (opens in a new tab)
Quelle: Meta AI (opens in a new tab)
Die Lizenzinformationen für die Llama 3 Modelle können auf der Modellkarte (opens in a new tab) gefunden werden.
Ausführliche Bewertung von Llama 3
Hier folgt eine längere Bewertung von Llama 3: