LLM Agenten
Agenten, die auf LLMs basieren, im Folgenden auch kurz als LLM-Agenten bezeichnet, integrieren LLM-Anwendungen, die komplexe Aufgaben durch die Verwendung einer Architektur ausführen können, die LLMs mit Schlüsselmodulen wie Planung und Speicher kombiniert. Beim Aufbau von LLM-Agenten dient ein LLM als Hauptcontroller oder „Gehirn“, das einen Ablauf von Operationen steuert, der erforderlich ist, um eine Aufgabe oder Benutzeranfrage zu vervollständigen. Der LLM-Agent kann Schlüsselmodule wie Planung, Speicher und Werkzeugnutzung benötigen.
Um den Nutzen eines LLM-Agenten besser zu veranschaulichen, nehmen wir an, dass wir daran interessiert sind, ein System zu entwickeln, das die folgende Frage beantworten kann:
Wie hoch ist die durchschnittliche tägliche Kalorienaufnahme für 2023 in den Vereinigten Staaten?
Die obige Frage könnte möglicherweise mithilfe eines LLMs beantwortet werden, das bereits über das Wissen verfügt, das benötigt wird, um die Frage direkt zu beantworten. Wenn das LLM nicht über das relevante Wissen verfügt, um die Frage zu beantworten, ist es möglich, ein einfaches RAG-System zu verwenden, bei dem ein LLM Zugang zu gesundheitsbezogenen Informationen oder Berichten hat. Stellen wir nun dem System eine komplexere Frage wie die folgende:
Wie hat sich der Trend der durchschnittlichen täglichen Kalorienaufnahme unter Erwachsenen im letzten Jahrzehnt in den Vereinigten Staaten verändert, und welchen Einfluss könnte dies auf die Fettleibigkeitsraten haben? Kannst du zusätzlich eine grafische Darstellung des Trends der Fettleibigkeitsraten über diesen Zeitraum bereitstellen?
Um eine solche Frage zu beantworten, reicht die Verwendung eines LLMs allein nicht aus. Man kann das LLM mit einer externen Wissensbasis kombinieren, um ein RAG-System zu bilden, aber das ist wahrscheinlich immer noch nicht genug, um die komplexe Anfrage oben zu beantworten. Dies liegt daran, dass die komplexe Frage oben ein LLM dazu erfordert, die Aufgabe in Teilabschnitte zu untergliedern, die mithilfe von Werkzeugen und einem Ablauf von Operationen adressiert werden können, der zu einer gewünschten endgültigen Antwort führt. Eine mögliche Lösung besteht darin, einen LLM-Agenten zu entwickeln, der Zugang zu einer Such-API, gesundheitsbezogenen Publikationen und öffentlichen/privaten Gesundheitsdatenbanken hat, um relevante Informationen bezüglich der Kalorienaufnahme und Fettleibigkeit bereitzustellen.
Zusätzlich benötigt das LLM Zugang zu einem „Code-Interpreter“-Werkzeug, das hilft, relevante Daten zu verwenden, um nützliche Diagramme zu erstellen, die Trends bei Fettleibigkeit verstehen helfen. Dies sind die möglichen high-level Komponenten des hypothetischen LLM-Agenten, aber es gibt noch wichtige Überlegungen wie die Erstellung eines Plans zur Adressierung der Aufgabe und der potenzielle Zugang zu einem Speichermodul, das dem Agenten hilft, den Zustand des Ablaufs der Operationen, Beobachtungen und des allgemeinen Fortschritts zu verfolgen.
LLM-Agenten-Framework
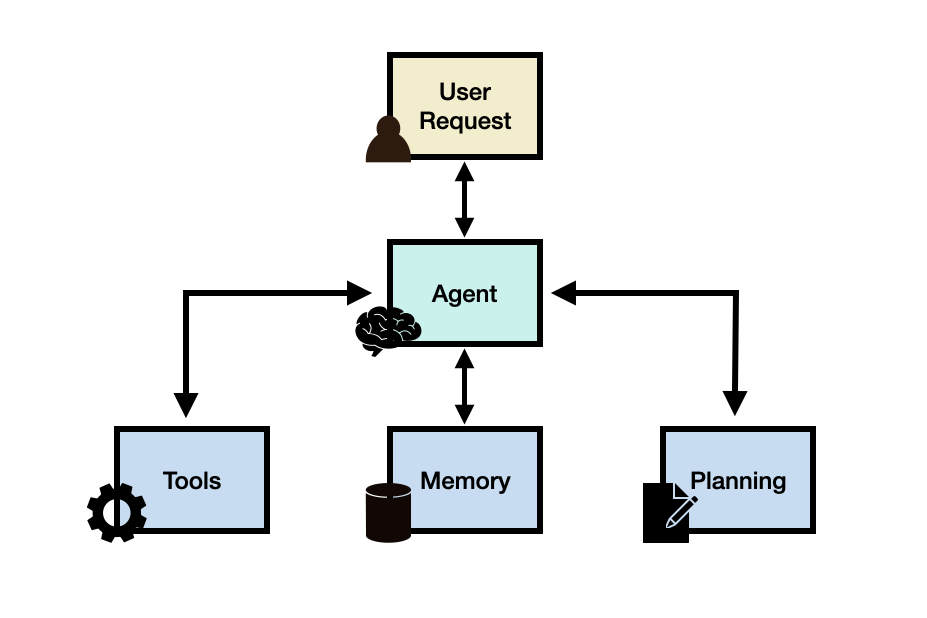
Allgemein gesprochen kann ein LLM-Agenten-Framework aus den folgenden Kernkomponenten bestehen:
- Benutzeranfrage (user request) - eine Benutzerfrage oder -anfrage
- Agent/Gehirn - der Kernagent als Koordinator
- Planung (planning) - unterstützt den Agenten bei der Planung zukünftiger Aktionen
- Speicher (memory) - verwaltet die vergangenen Verhaltensweisen des Agenten
Agent
Ein großes Sprachmodell (LLM) mit allgemeinen Fähigkeiten dient als Hauptgehirn, Agentenmodul oder Koordinator des Systems. Diese Komponente wird mithilfe einer Prompt-Vorlage aktiviert, die wichtige Details darüber enthält, wie der Agent operieren wird und auf welche Werkzeuge er Zugriff haben wird (zusammen mit Werkzeugdetails).
Obwohl nicht zwingend erforderlich, kann einem Agenten ein Profil zugeordnet oder eine Persona zugewiesen werden, um seine Rolle zu definieren. Diese Profilierungsinformationen werden typischerweise im Prompt geschrieben, welcher spezifische Details wie Rollendetails, Persönlichkeit, soziale Informationen und andere demografische Informationen enthalten kann. Gemäß [Wang et al. 2023] beinhalten die Strategien zur Definition eines Agentenprofils manuelle Anpassungen, LLM-generiert oder datengesteuert.
Planung
Planung ohne Feedback
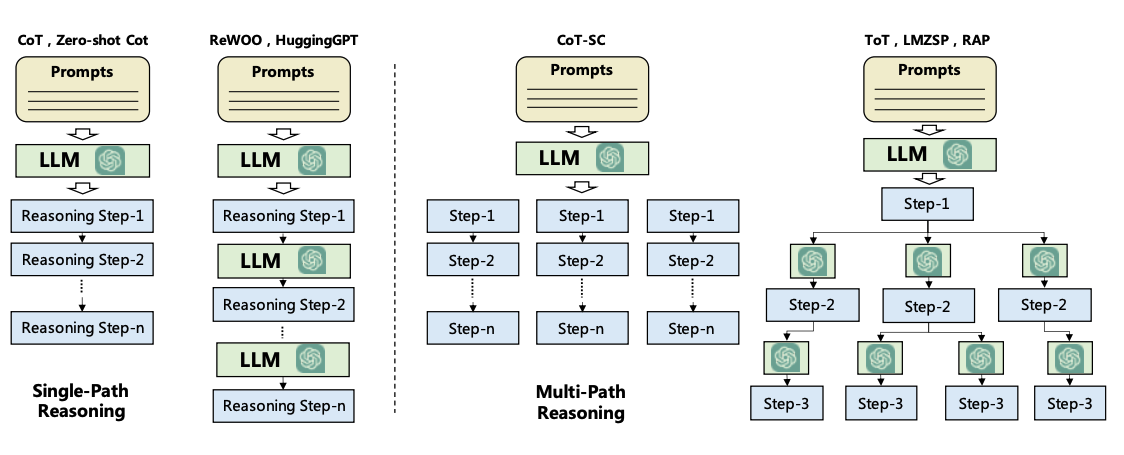
Das Planungsmodul hilft, die notwendigen Schritte oder Teilaufgaben zu untergliedern, die der Agent einzeln lösen wird, um die Benutzeranfrage zu beantworten. Dieser Schritt ist wichtig, um es dem Agenten zu ermöglichen, besser über das Problem nachzudenken und eine zuverlässige Lösung zu finden. Das Planungsmodul wird ein LLM nutzen, um einen detaillierten Plan zu zerlegen, der Teilaufgaben zur Adressierung der Benutzerfrage umfassen wird. Beliebte Techniken für die Aufgabenzerlegung umfassen Prompt Chaining (opens in a new tab) und Tree of Thought (opens in a new tab), die jeweils als Einzelpfad-Schlussfolgerung und Mehrpfad-Schlussfolgerung kategorisiert werden können. Unten ist eine Abbildung, die unterschiedliche Strategien vergleicht, wie in Wang et al., 2023 (opens in a new tab) formalisiert:
Planung mit Feedback
Die oben genannten Planungsmodule beinhalten kein Feedback, was es herausfordernd macht, eine langfristige Planung zur Lösung komplexer Aufgaben zu erreichen. Um diese Herausforderung zu bewältigen, kann man einen Mechanismus nutzen, der es dem Modell ermöglicht, den Ausführungsplan basierend auf vergangenen Aktionen und Beobachtungen iterativ zu reflektieren und zu verfeinern. Das Ziel ist, vergangene Fehler zu korrigieren und zu verbessern, was dazu beiträgt, die Qualität der endgültigen Ergebnisse zu verbessern. Dies ist besonders wichtig bei komplexen realweltlichen Umgebungen und Aufgaben, bei denen Versuch und Irrtum entscheidend für die Vervollständigung von Aufgaben sind. Zwei beliebte Methoden für diesen Reflexions- oder Kritikmechanismus umfassen ReAct (opens in a new tab) und Reflexion (opens in a new tab).
Als Beispiel kombiniert ReAct Argumentation und Handeln mit dem Ziel, einem LLM zu ermöglichen, komplexe Aufgaben zu lösen, indem es zwischen einer Reihe von Schritten wechselt (wiederholt N-mal): Gedanke, Aktion und Beobachtung. ReAct erhält Feedback aus der Umgebung in Form von Beobachtungen. Andere Arten von Feedback können menschliches und Modell-Feedback einschließen. Die Abbildung unten zeigt ein Beispiel von ReAct und die verschiedenen Schritte, die bei der Beantwortung von Fragen beteiligt sind:

Erfahren Sie mehr über ReAct hier:
Speicher
Das Speichermodul hilft, die internen Protokolle des Agenten zu speichern, einschließlich vergangener Gedanken, Aktionen und Beobachtungen aus der Umwelt, einschließlich aller Interaktionen zwischen Agent und Benutzer. Es gibt zwei Haupttypen von Speichern, die in der LLM-Agenten-Literatur berichtet wurden:
- Kurzzeitspeicher - umfasst Kontextinformationen über die aktuellen Situationen des Agenten; dies wird typischerweise durch In-Kontext-Lernen realisiert, was bedeutet, dass es kurz und begrenzt ist aufgrund von Kontextfenster-Einschränkungen.
- Langzeitspeicher - umfasst die vergangenen Verhaltensweisen und Gedanken des Agenten, die über einen längeren Zeitraum behalten und abgerufen werden müssen; dies nutzt oft einen externen Vektorspeicher, der durch schnellen und skalierbaren Abruf zugänglich ist, um dem Agenten bei Bedarf relevante Informationen zu liefern.
Hybrid-Speicher integriert sowohl Kurzzeit- als auch Langzeitspeicher, um die Fähigkeit eines Agenten zur langfristigen Argumentation und zur Ansammlung von Erfahrungen zu verbessern.
Es gibt auch unterschiedliche Speicherformate, die bei der Entwicklung von Agenten berücksichtigt werden müssen. Repräsentative Speicherformate umfassen natürliche Sprache, Einbettungen, Datenbanken und strukturierte Listen, unter anderem. Diese können auch kombiniert werden, wie im Geist in Minecraft (GITM (opens in a new tab)), der eine Schlüssel-Wert-Struktur nutzt, bei der die Schlüssel durch natürliche Sprache repräsentiert werden und die Werte durch Einbettungsvektoren dargestellt werden.
Sowohl die Planungs- als auch die Speichermodule ermöglichen es dem Agenten, in einer dynamischen Umgebung zu operieren und es ihm zu ermöglichen, vergangene Verhaltensweisen effektiv zu erinnern und zukünftige Aktionen zu planen.
Werkzeuge
Werkzeuge entsprechen einem Satz von Werkzeug/en, der/die es dem LLM-Agenten ermöglicht, mit externen Umgebungen zu interagieren, wie z. B. Wikipedia Search API, Code-Interpreter und Mathematik-Engine. Werkzeuge könnten auch Datenbanken, Wissensdatenbanken und externe Modelle umfassen. Wenn der Agent mit externen Werkzeugen interagiert, führt er Aufgaben über Workflows aus, die dem Agenten helfen, Beobachtungen oder notwendige Informationen zu erhalten, um Teilaufgaben zu vervollständigen und die Benutzeranfrage zu erfüllen. In unserer anfänglichen gesundheitsbezogenen Anfrage ist ein Code-Interpreter ein Beispiel für ein Werkzeug, das Code ausführt und die erforderlichen Diagramminformationen generiert, die vom Benutzer angefragt werden.
Werkzeuge werden von LLMs auf verschiedene Weisen genutzt:
- MRKL (opens in a new tab) ist ein Framework, das LLMs mit Expertenmodulen kombiniert, die entweder LLMs oder symbolisch sind (Rechner oder Wetter-API).
- Toolformer (opens in a new tab) verfeinert LLMs zur Verwendung von externen Tool-APIs.
- Funktionsaufruf (opens in a new tab) - erweitert LLMs mit der Fähigkeit zur Werkzeugnutzung, die die Definition eines Satzes von Tool-APIs umfasst und diese als Teil einer Anfrage dem Modell zur Verfügung stellt.
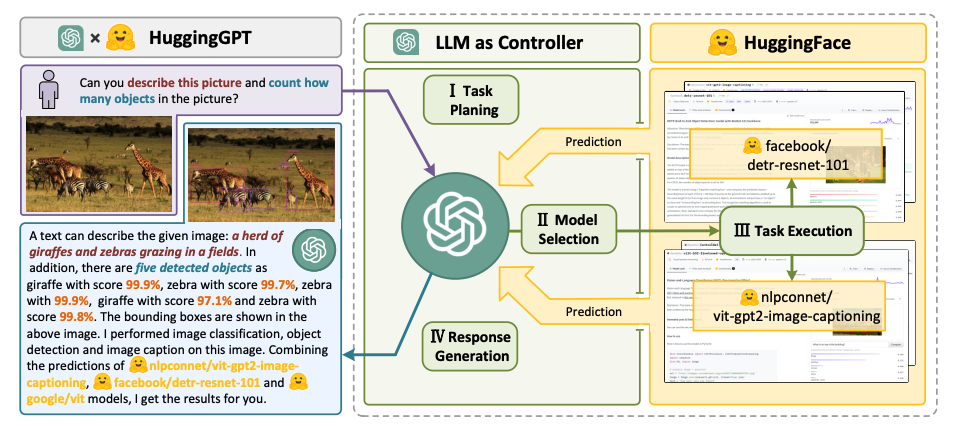
- HuggingGPT (opens in a new tab) - ein LLM-betriebener Agent, der LLMs als Aufgabenplaner nutzt, um verschiedene existierende KI-Modelle (basierend auf Beschreibungen) zu verbinden, um KI-Aufgaben zu lösen.
Anwendungen von LLM-Agenten
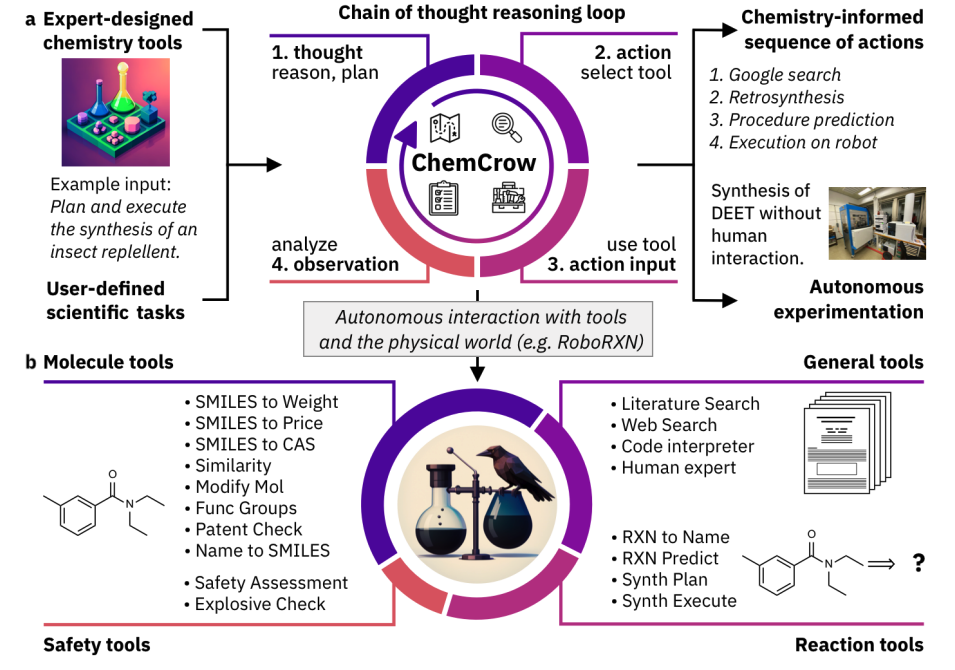 Der ChemCrow-Agent, entworfen, um Aufgaben in organischer Synthese, Arzneimittelforschung und Materialdesign zu vervollständigen. Abbildungsquelle: Bran et al., 2023
Der ChemCrow-Agent, entworfen, um Aufgaben in organischer Synthese, Arzneimittelforschung und Materialdesign zu vervollständigen. Abbildungsquelle: Bran et al., 2023
In diesem Abschnitt heben wir Beispiele für Domänen und Fallstudien hervor, in denen LLM-basierte Agenten effektiv angewendet wurden, aufgrund ihrer komplexen Argumentations- und Allgemeinwissensfähigkeiten.
Bemerkenswerte LLM-basierte Agenten
- Ma et al. (2023) (opens in a new tab) analysieren die Wirksamkeit von Gesprächsagenten zur Unterstützung des mentalen Wohlbefindens und finden heraus, dass der Agent Benutzern helfen kann, mit Ängsten umzugehen, aber manchmal schädlichen Inhalt produzieren kann.
- Horton (2023) (opens in a new tab) gibt LLM-basierten Agenten Ausstattung, Präferenzen und Persönlichkeiten, um menschliche ökonomische Verhaltensweisen in simulierten Szenarien zu erkunden.
- Generative Agents (opens in a new tab) und AgentSims (opens in a new tab) zielen beide darauf ab, das menschliche tägliche Leben in einer virtuellen Stadt zu simulieren, indem sie mehrere Agenten konstruieren.
- Blind Judgement (opens in a new tab) setzt mehrere Sprachmodelle ein, um die Entscheidungsprozesse mehrerer Richter zu simulieren; Vorhersage der Entscheidungen des realen Obersten Gerichtshofs mit besserer als zufälliger Genauigkeit.
- Ziems et al. (2023) (opens in a new tab) stellt Agenten vor, die Forschern bei Aufgaben wie dem Generieren von Zusammenfassungen, Schreiben von Skripten und Extrahieren von Schlüsselwörtern helfen können.
- ChemCrow (opens in a new tab) ist ein chemischer LLM-Agent, der chemiebezogene Datenbanken nutzt, um autonom die Synthese von Insektenschutzmitteln, drei Organokatalysatoren und die geleitete Entdeckung eines neuen Chromophors zu planen und auszuführen.
- [Boiko et al. (2023)] kombiniert mehrere LLMs zur Automatisierung des Designs, der Planung und der Ausführung wissenschaftlicher Experimente.
- Math Agents unterstützen Forscher beim Erkunden, Entdecken, Lösen und Beweisen mathematischer Probleme. EduChat (opens in a new tab) und CodeHelp (opens in a new tab) sind zwei weitere bemerkenswerte Beispiele für LLM-Agenten, entwickelt für die Bildung.
- Mehta et al. (2023) (opens in a new tab) schlagen ein interaktives Framework vor, das es menschlichen Architekten ermöglicht, mit KI-Agenten zu interagieren, um Strukturen in einer 3D-Simulationsumgebung zu konstruieren.
- ChatDev (opens in a new tab), ToolLLM (opens in a new tab), MetaGPT (opens in a new tab) sind bemerkenswerte Beispiele, bei denen KI-Agenten das Potenzial zeigen, das Programmieren, Debuggen, Testen zu automatisieren und bei anderen Softwareentwicklungsaufgaben zu helfen.
- D-Bot (opens in a new tab) ein LLM-basierter Datenbankadministrator, der kontinuierlich Erfahrung in der Datenbankwartung erwirbt und Diagnose- und Optimierungsratschläge für Datenbanken bereitstellt.
- IELLM (opens in a new tab) wendet LLMs an, um Herausforderungen in der Öl- und Gasindustrie anzugehen.
- Dasgupta et al. 2023 (opens in a new tab) präsentiert ein einheitliches Agentensystem für verkörperte Argumentation und Aufgabenplanung.
- OS-Copilot (opens in a new tab) ein Framework zum Aufbau von generalistischen Agenten, die mit umfassenden Elementen in einem Betriebssystem (OS) interagieren können, einschließlich des Webs, Code-Terminals, Dateien, Multimedia und verschiedener Drittanbieteranwendungen.
LLM Agent Werkzeuge
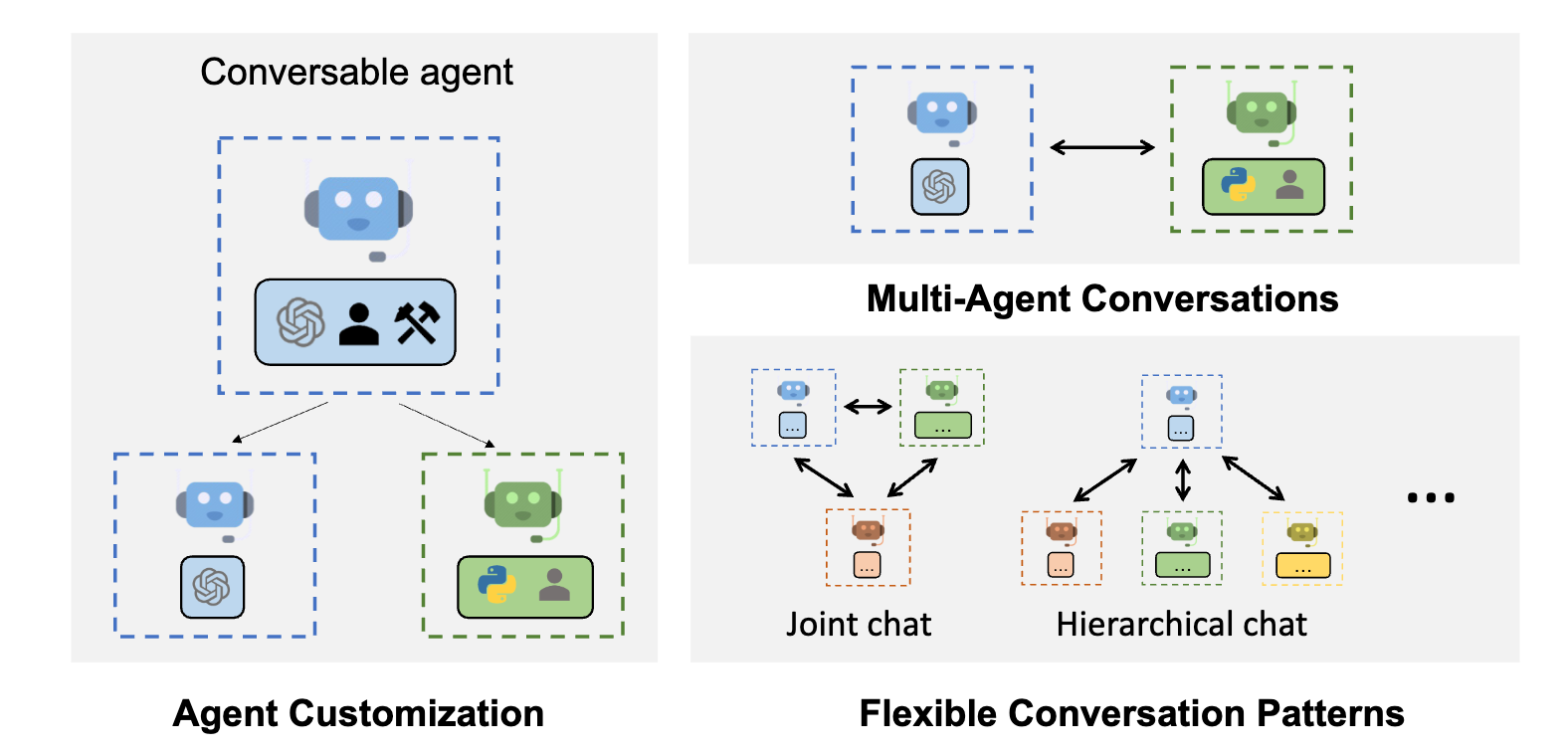 AutoGen-Funktionen; Abbildungsquelle: https://microsoft.github.io/autogen (opens in a new tab)
AutoGen-Funktionen; Abbildungsquelle: https://microsoft.github.io/autogen (opens in a new tab)
Im Folgenden sind bemerkenswerte Beispiele von Werkzeugen und Frameworks aufgeführt, die zum Erstellen von LLM-Agenten verwendet werden:
- LangChain (opens in a new tab): ein Framework zur Entwicklung von Anwendungen und Agenten, die von Sprachmodellen angetrieben werden.
- AutoGPT (opens in a new tab): stellt Werkzeuge zum Erstellen von KI-Agenten bereit.
- Langroid (opens in a new tab): Vereinfacht die Erstellung von LLM-Anwendungen mit Multi-Agent-Programmierung: Agenten als First-Class-Citizens, die über Nachrichten an Aufgaben zusammenarbeiten.
- AutoGen (opens in a new tab): ein Framework, das die Entwicklung von LLM-Anwendungen mit mehreren Agenten ermöglicht, die miteinander kommunizieren können, um Aufgaben zu lösen.
- OpenAgents (opens in a new tab): eine offene Plattform zur Nutzung und Hosting von Sprachagenten in der realen Welt.
- LlamaIndex (opens in a new tab) - ein Framework zum Verbinden von benutzerdefinierten Datenquellen mit großen Sprachmodellen.
- GPT Engineer (opens in a new tab): automatisiert die Codegenerierung, um Entwicklungsaufgaben zu erledigen.
- DemoGPT (opens in a new tab): autonomer KI-Agent zum Erstellen interaktiver Streamlit-Apps.
- GPT Researcher (opens in a new tab): ein autonomer Agent, der für umfassende Online-Recherchen zu einer Vielzahl von Aufgaben konzipiert ist.
- AgentVerse (opens in a new tab): entwickelt, um die Einsatzmöglichkeiten mehrerer LLM-basierter Agenten in verschiedenen Anwendungen zu erleichtern.
- Agents (opens in a new tab): eine Open-Source-Bibliothek/Framework zum Erstellen autonomer Sprachagenten. Die Bibliothek unterstützt Funktionen wie Langzeit-Kurzzeitspeicher, Werkzeugnutzung, Webnavigation, Multi-Agent-Kommunikation und brandneue Funktionen einschließlich Mensch-Agent-Interaktion und symbolische Steuerung.
- BMTools (opens in a new tab): erweitert Sprachmodelle mit Werkzeugen und dient als Plattform für die Gemeinschaft zum Erstellen und Teilen von Werkzeugen.
- crewAI (opens in a new tab): KI-Agent-Framework neu gedacht für Ingenieure, bietet leistungsstarke Fähigkeiten mit Einfachheit zum Erstellen von Agenten und Automatisierungen.
- Phidata (opens in a new tab): ein Toolkit zum Erstellen von KI-Assistenten durch Funktionsaufrufe.
LLM Agent Bewertung
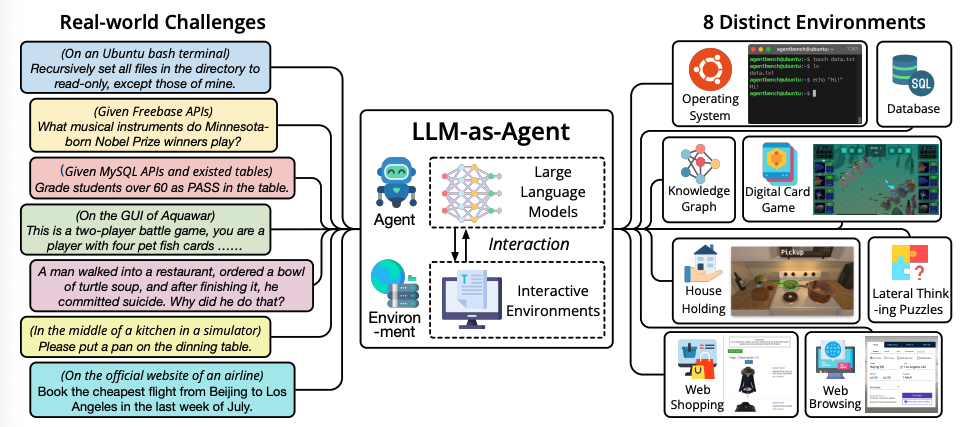 AgentBench Benchmark zur Bewertung von LLM-als-Agent in realen Herausforderungen und 8 verschiedenen Umgebungen. Abbildungsquelle: Liu et al. 2023
AgentBench Benchmark zur Bewertung von LLM-als-Agent in realen Herausforderungen und 8 verschiedenen Umgebungen. Abbildungsquelle: Liu et al. 2023
Ähnlich wie bei der Bewertung von LLM selbst, stellt die Bewertung von LLM-Agenten eine herausfordernde Aufgabe dar. Laut Wang et al., (2023) umfassen gängige Bewertungsmethoden:
- Menschliche Annotation: Umfasst menschliche Evaluatoren, die die Ergebnisse der LLM direkt über verschiedene Aspekte bewerten, die in der Anwendung wichtig sind, wie Ehrlichkeit, Hilfsbereitschaft, Engagement, Unvoreingenommenheit und mehr.
- Turing-Test: Menschliche Evaluatoren werden gebeten, Ergebnisse von echten Menschen und Agenten zu vergleichen, wobei nicht unterscheidbare Ergebnisse bedeuten, dass Agenten eine menschenähnliche Leistung erzielen können.
- Metriken: Dabei handelt es sich um sorgfältig entworfene Metriken, die die Qualität der Agenten widerspiegeln. Zu den bemerkenswerten Metriken gehören Aufgabenerfolgsmetriken, menschliche Ähnlichkeitsmetriken und Effizienzmetriken.
- Protokolle: Entsprechen gängigen Bewertungsprotokollen, die bestimmen, wie die Metriken verwendet werden. Beispiele hierfür sind Simulationen aus der realen Welt, soziale Bewertungen, Mehrfachaufgabenbewertungen und Softwaretests.
- Benchmarks: Mehrere Benchmarks wurden entwickelt, um LLM-Agenten zu bewerten. Bemerkenswerte Beispiele umfassen ALFWorld (opens in a new tab), IGLU (opens in a new tab), Tachikuma (opens in a new tab), AgentBench (opens in a new tab), SocKET (opens in a new tab), AgentSims (opens in a new tab), ToolBench (opens in a new tab), WebShop (opens in a new tab), Mobile-Env (opens in a new tab), WebArena (opens in a new tab), GentBench (opens in a new tab), RocoBench (opens in a new tab), EmotionBench (opens in a new tab), PEB (opens in a new tab), ClemBench (opens in a new tab) und E2E (opens in a new tab).
Herausforderungen
LLM-Agenten stehen noch am Anfang, daher gibt es viele Herausforderungen und Einschränkungen beim Aufbau:
- Rollenübernahmefähigkeit: LLM-basierte Agenten müssen sich in der Regel eine Rolle aneignen, um Aufgaben in einem Bereich effektiv abzuschließen. Für Rollen, die das LLM nicht gut charakterisiert, ist es möglich, das LLM mit Daten zu feintunen, die ungewöhnliche Rollen oder psychologische Charaktere darstellen.
- Langfristige Planung und begrenzte Kontextlänge: die Planung über eine lange Geschichte bleibt eine Herausforderung, die zu Fehlern führen könnte, von denen der Agent sich möglicherweise nicht erholt. LLMs sind auch in der Kontextlänge begrenzt, die sie unterstützen können, was zu Einschränkungen führen könnte, die die Fähigkeiten des Agenten einschränken, wie z.B. die Nutzung des Kurzzeitgedächtnisses.
- Generalisierte menschliche Ausrichtung: es ist auch herausfordernd, Agenten mit vielfältigen menschlichen Werten auszurichten, was auch bei Standard-LLMs üblich ist. Eine potenzielle Lösung beinhaltet die Möglichkeit, das LLM durch das Entwerfen fortgeschrittener Prompting-Strategien neu auszurichten.
- Prompt-Robustheit und -Zuverlässigkeit: ein LLM-Agent kann mehrere Prompts umfassen, die dazu dienen, die verschiedenen Module wie Speicher und Planung anzutreiben. Es ist üblich, auf Zuverlässigkeitsprobleme in LLMs zu stoßen, sogar bei den geringfügigsten Änderungen an Prompts. LLM-Agenten beinhalten ein gesamtes Prompt-Framework, was sie anfälliger für Robustheitsprobleme macht. Die potenziellen Lösungen umfassen das Ausarbeiten von Prompt-Elementen durch Versuch und Irrtum, das automatische Optimieren/Einstellen von Prompts oder das automatische Generieren von Prompts mithilfe von GPT. Ein weiteres häufiges Problem bei LLMs ist Halluzination, das auch bei LLM-Agenten weit verbreitet ist. Diese Agenten stützen sich auf natürliche Sprache, um mit externen Komponenten zu interagieren, die widersprüchliche Informationen einführen könnten und zu Halluzinationen und Faktualitätsproblemen führen könnten.
- Wissensgrenze: ähnlich wie bei Wissensmismatch-Problemen, die zu Halluzinationen oder Faktualitätsproblemen führen könnten, ist es herausfordernd, den Wissensumfang von LLMs zu kontrollieren, was die Wirksamkeit von Simulationen erheblich beeinflussen kann. Konkret könnte das interne Wissen eines LLMs Vorurteile einführen oder Wissen nutzen, das dem Nutzer unbekannt ist, was das Verhalten des Agenten bei der Bedienung in bestimmten Umgebungen beeinflussen könnte.
- Effizienz: LLM-Agenten umfassen eine erhebliche Anzahl von Anforderungen, die vom LLM bearbeitet werden, was die Effizienz von Agentenaktionen beeinträchtigen könnte, da sie stark von der LLM-Inferenzgeschwindigkeit abhängt. Auch die Kosten sind ein Anliegen beim Einsatz mehrerer Agenten.
Referenzen
- LLM Powered Autonomous Agents (opens in a new tab)
- MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning (opens in a new tab)
- A Survey on Large Language Model based Autonomous Agents (opens in a new tab)
- The Rise and Potential of Large Language Model Based Agents: A Survey (opens in a new tab)
- Large Language Model based Multi-Agents: A Survey of Progress and Challenges (opens in a new tab)
- Cognitive Architectures for Language Agents (opens in a new tab)
- Introduction to LLM Agents (opens in a new tab)
- LangChain Agents (opens in a new tab)
- Building Your First LLM Agent Application (opens in a new tab)
- Building LLM applications for production (opens in a new tab)
- Awesome LLM agents (opens in a new tab)
- Awesome LLM-Powered Agent (opens in a new tab)
- Functions, Tools and Agents with LangChain (opens in a new tab)