OLMo
In diesem Leitfaden bieten wir einen Überblick über das Open Language Model (OLMo), einschließlich Prompts und Nutzungsbeispielen. Der Leitfaden enthält auch Tipps, Anwendungen, Einschränkungen, wissenschaftliche Arbeiten und zusätzliches Lesematerial, das sich auf OLMo bezieht.
Einführung in OLMo
Das Allen Institute of AI hat ein neues Open Language Model und Framework namens OLMo veröffentlicht (opens in a new tab). Diese Bemühung zielt darauf ab, vollen Zugang zu Daten, Trainingscode, Modellen, Evaluierungscode zu bieten, um die gemeinsame Studie von Sprachmodellen zu beschleunigen.
Die erste Veröffentlichung umfasst vier Varianten im 7-Milliarden-Parameter-Maßstab und ein Modell im 1-Milliarden-Maßstab, alle trainiert mit mindestens 2 Billionen Tokens. Dies markiert die erste von vielen Veröffentlichungen, die auch ein bevorstehendes 65-Milliarden-OLMo-Modell umfasst.
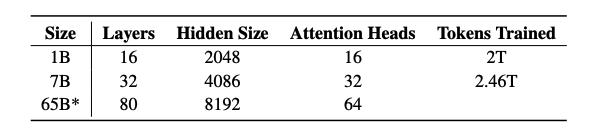
Die Veröffentlichungen beinhalten:
- vollständige Trainingsdaten, einschließlich des Codes (opens in a new tab), der die Daten erzeugt
- vollständige Modellgewichte, Trainingscode (opens in a new tab), Logs, Metriken und Inferenzcode
- mehrere Checkpoints pro Modell
- Evaluierungscode (opens in a new tab)
- Feinabstimmungscode
Aller Code, Gewichte und Zwischencheckpoints werden unter der Apache 2.0-Lizenz (opens in a new tab) veröffentlicht.
OLMo-7B
Sowohl die OLMo-7B- als auch die OLMo-1B-Modelle verwenden eine Decoder-only-Transformator-Architektur. Sie folgen Verbesserungen anderer Modelle wie PaLM und Llama:
- keine Verzerrungen (biases)
- eine nicht-parametrische Layernorm
- SwiGLU-Aktivierungsfunktion
- Rotative Positions-Embeddings (RoPE)
- ein Vokabular von 50.280
Dolma-Datensatz
Diese Veröffentlichung umfasst auch die Freigabe eines Pre-Training-Datensatzes namens Dolma (opens in a new tab) -- ein vielfältiger, multi-source Korpus von 3 Billionen Tokens aus 5 Milliarden Dokumenten, erworben aus 7 verschiedenen Datenquellen. Die Erstellung von Dolma beinhaltet Schritte wie Sprachfilterung, Qualitätsfilterung, Inhaltsfilterung, Deduplizierung, Multi-Source-Mixing und Tokenisierung.
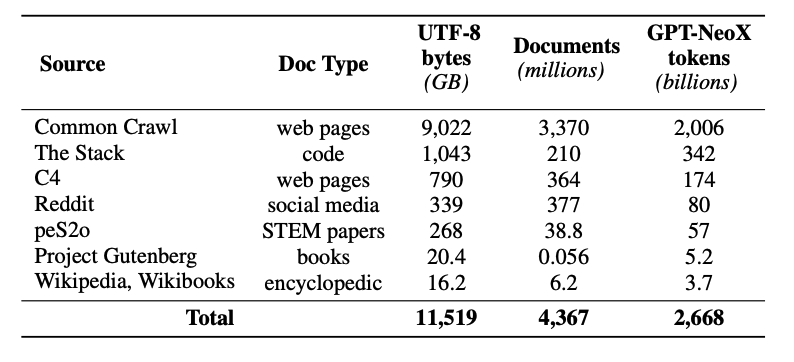
Der Trainingsdatensatz umfasst eine 2-Billionen-Token-Stichprobe aus Dolma. Die Tokens werden nach dem Anhängen eines speziellen EOS (End of Sentence)-Tokens an das Ende jedes Dokuments zusammengekettet. Die Trainingsinstanzen beinhalten Gruppen von aufeinanderfolgenden Chunks mit 2048 Tokens, die ebenfalls gemischt werden.
Weitere Trainingsdetails und Hardwarespezifikationen zum Trainieren der Modelle finden Sie im wissenschaftlichen Artikel.
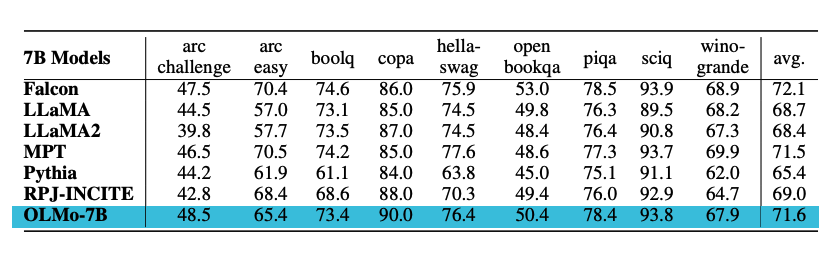
Ergebnisse
Die Modelle werden auf nachgelagerten Aufgaben mit dem Catwalk (opens in a new tab) evaluiert. Die OLMo-Modelle werden mit anderen mehreren öffentlich verfügbaren Modellen wie Falcon und Llama 2 verglichen. Insbesondere wird das Modell anhand einer Reihe von Aufgaben bewertet, die darauf abzielen, die Fähigkeiten des Modells zum commonsense Reasoning zu messen. Zum nachgelagerten Evaluierungskit gehören Datensätze wie piqa und hellaswag. Die Autoren führen eine Zero-Shot-Evaluierung durch, indem sie eine Rangklassifizierung verwenden (d. h., Vervollständigungen werden nach Wahrscheinlichkeit eingestuft), und die Genauigkeit wird berichtet. OLMo-7B übertrifft alle anderen Modelle bei 2 Endaufgaben und bleibt bei 8 von 9 Endaufgaben in den Top 3. Eine Zusammenfassung der Ergebnisse im Diagramm ist unten zu sehen.
Prompting-Leitfaden für OLMo
Demnächst...
Bildquellen: OLMo: Accelerating the Science of Language Models (opens in a new tab)