LM-geführtes Chain-of-Thought
Ein neues Paper von Lee et al. (2024) (opens in a new tab) schlägt vor, das Schlussfolgern in LLMs mit Hilfe kleiner Sprachmodelle zu verbessern.
Zunächst wird Wissenstransfer auf ein kleines LM angewendet, wobei die Begründungen vom großen LM erzeugt werden, in der Hoffnung, die Kluft in den Schlussfolgerungsfähigkeiten zu verringern.
Im Wesentlichen wird die Begründung durch das kleine LM generiert und die Antwortvorhersage dann dem eingefrorenen großen LM überlassen. Dieser ressourceneffiziente Ansatz vermeidet die Notwendigkeit, das große Modell feinabzustimmen, und überträgt stattdessen die Generierung der Begründung auf das kleine Sprachmodell.
Das mit Wissen angereicherte LM wird weiterhin mit Reinforcement Learning optimiert, wobei verschiedene an Begründungen und Aufgaben orientierte Belohnungssignale verwendet werden.
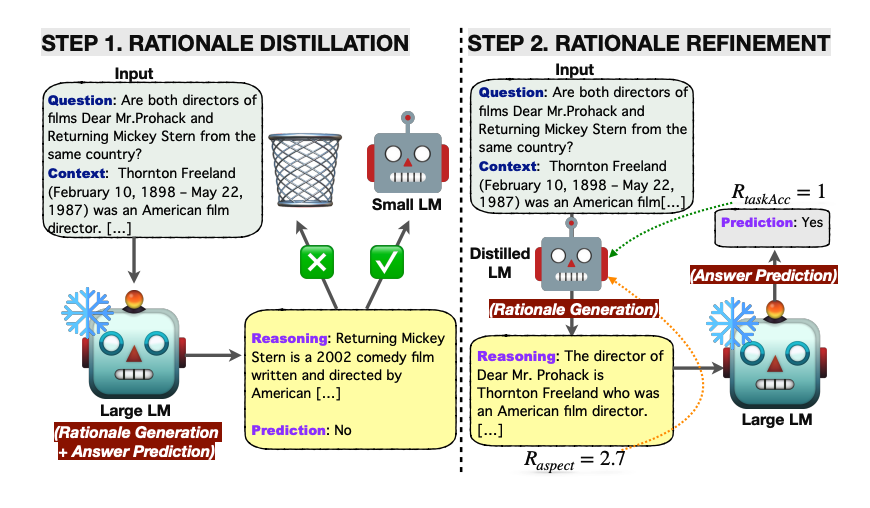 Quelle: https://arxiv.org/pdf/2404.03414.pdf (opens in a new tab)
Quelle: https://arxiv.org/pdf/2404.03414.pdf (opens in a new tab)
Das Framework wird auf Multi-Hop-Extraktionsfragen getestet und übertrifft alle Baselines hinsichtlich der Genauigkeit der Antwortvorhersage. RL hilft, die Qualität der generierten Begründungen zu verbessern, was wiederum die Leistung der Fragenbeantwortung verbessert.
Der in diesem Paper vorgeschlagene LM-geführte CoT-Prompt-Ansatz übertrifft sowohl das Standard-Prompting als auch das CoT-Prompting. Selbstkonsistenz-Decodierung verbessert außerdem die Performance.
Dieser Ansatz zeigt einen klugen Einsatz kleiner Sprachmodelle für die Generierung von Begründungen. Die Ergebnisse sind bemerkenswert, da größere Sprachmodelle für diese Fähigkeit gegenüber kleineren bevorzugt werden. Entwickler sollten tief über die Zerlegung von Aufgaben in dieser Weise nachdenken. Nicht alles muss von den großen Modellen erledigt werden. Beim Feinabstimmen ist es nützlich, darüber nachzudenken, welchen genauen Aspekt Sie optimieren möchten und zu testen, ob ein kleines Sprachmodell dies für Sie erledigen kann.